Technology is advancing at a rapid pace, and while it may feel overwhelming at times, it’s making our daily tasks easier.
From ordering our morning coffee with a voice command to finding the quickest route to the office, these conveniences have become second nature. But what if your devices could understand and interact with the world around us in the same way a human could?
With the power of artificial intelligence (AI) and computer vision technology, now we can.
What is you only look once (YOLO)?
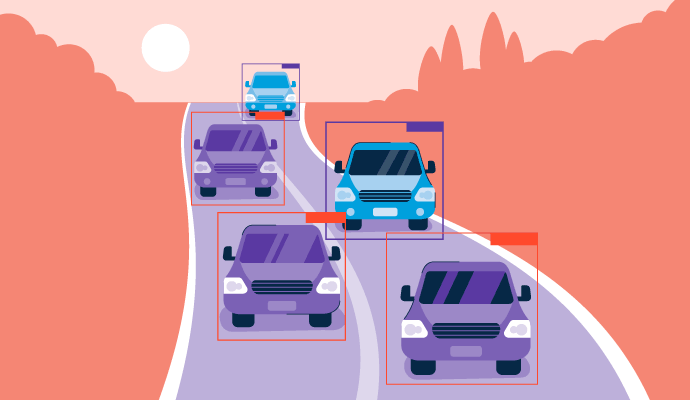
You only look once, or YOLO, is a real-time object detection algorithm first developed in 2015. It predicts the probability that an object is present within a picture or video. It’s a specific algorithm that enhances the current field of object detection in computer vision technology, where objects in images are localized and identified.
YOLO only needs to review the visual once to make these predictions, hence its name, and can also be referred to as single-shot object detection (SSD). It is an important part of the object detection process that many image recognition software products use to understand what visual media is depicting.
By using end-to-end neural networks, this algorithm can predict both the location (bounding boxes) and identity (classification) of objects in an image simultaneously. This was a leap from traditional object detection algorithms, which repurposed existing classifiers to predict this information.
How You Only Look Once works
YOLO relies on a single convolutional neural network (CNN), a key component of deep learning and a type of AI network that filters model inputs to scan for recognizable patterns. The layers in these networks are formatted to detect the simplest patterns first, before moving into more complex ones.
Although CNNs are used for more than image processing, they’re a fundamental part of YOLO architecture. When an image is input into a YOLO-based model, it goes through several steps to detect objects within that visual. Here’s a breakdown:
- Input image: The entire image, whether a static photo, graphic, or video format, is passed through the model. Features of the image are extracted and passed through connected layers to predict the classifications and bounding box coordinates.
- Grid division: The input image is then divided into boxes in a grid formation. Each small square or cell of the grid is tasked with detecting objects within its section, along with providing a probability or confidence value for any detected object.
- Object detection: If a grid is predicted to contain an object, it will be highlighted as significant cells. The model then determines the type of object and its location within the grid in a single pass.
- Bounding box scoring: The model draws boxes around the detected objects, known as bounding boxes. Each grid cell can generate multiple bounding boxes if there’s more than one object in that cell. Bounding boxes can also overlap cells to completely encompass each object in the whole image. A confidence score is assigned to each bounding box that represents how likely the prediction is to be correct.
- Output: After the grid squares have been assessed, the final output will list all objects within the image, along with each bounding box and its label. As part of post-processing, non-max suppression (NMS) will take place to remove overlapping boxes, ensuring each object is represented by only one box with the highest confidence score. This step improves the accuracy of object detection and makes the entire process more efficient by filtering out additional noise to create a cleaner output.
Quer aprender mais sobre Software de Reconhecimento de Imagem? Explore os produtos de Reconhecimento de Imagem.
Types of YOLO in object detection
Since its development, YOLO has been through several iterations that have built in updated technology and have created a faster, more efficient workflow. Here’s a brief rundown of YOLO v1-v6 and a look at where we are today:
- YOLOv1: The original algorithm was focused primarily on object detection as a regression problem rather than the traditional classification approaches, which was groundbreaking at the time. This foundation is still used in YOLO models today.
- YOLOv2: Also known as YOLO 9000, this version built on the original concepts of YOLO and addressed some of the limitations of the first model. Anchor boxes were introduced as pre-determined boxes within the grid, with unique aspect ratios and scales. This made predicting bounding boxes easier and fit better with actual objects in the image. The version also included updates to handle higher-resolution images without slowing down processing times.
- YOLOv3: This version introduced a technique known as “feature pyramid network” (FPN), which was used to detect different sized objects within the image. Processing speed was also boosted in the third version of YOLO through the use of Darknet-53.
- YOLOv4: With an updated version of Darknet, CSPDarnet, the fourth version of YOLO, was significantly faster and more accurate than previous iterations. Accuracy improved by around 0.5% on average thanks to the introduction of a technique known as “cross-state partial connection” or CSP, where multiple models were introduced at the same time to combine their prediction abilities.
- YOLOv5: Introduced in 2020, the fifth version of YOLO introduced an updated neural network architecture called EfficientDet. EfficientDet was a series of image classification models designed to improve computational accuracy and memory usage while still achieving the highest levels of output accuracy. Anchor boxes were no longer needed with version 5, with a single convolutional layer able to predict bounding boxes of objects directly, no matter their shape or size.
- YOLOv6: The introduction of a new, lighter neural network meant that version 6 of YOLO ran more efficiently and with fewer resources needed. Data augmentation was also introduced during training, which allows the model to still recognize objects when flipped, rotated, or scaled in the input image.
The most recent updates to YOLO, versions 7 through 9, have continued to see greater speed and accuracy improvements as the algorithm is adapted based on current deep learning breakthroughs. The learning capacity of the algorithm has significantly increased with these newer models, allowing object detection to still be possible with blurred or incomplete image data.
Industries that use You Only Look Once
There are numerous ways that YOLO can be implemented in everyday life, but some industries benefit more from this technology than others.
Security
Surveillance systems become more complex every year, helping to keep us safe wherever we are. YOLO is often used to detect individuals being monitored by law enforcement through CCTV and security camera systems while also monitoring for crimes such as shoplifting or assault taking place in real-time.
Healthcare
Like other forms of object detection and image recognition, YOLO can be used in real-time medical care and imaging treatment. Several studies have found widespread usage of YOLO throughout this industry, including surgical procedures where organ detection is necessary due to the biological diversity of different patients.
Both 2D and 3D scans can quickly and accurately pinpoint organ placement, providing insight into potential issues that medical imaging is used to detect.
Agriculture
The development of AI has helped the agricultural industry significantly, allowing farmers to monitor their crops at all times without the need for manual supervision. YOLO and agriculture robotics have replaced manual picking and harvesting in many cases. It is also used to identify when crops are at their peak ripeness for picking based on color or size characteristics of the objects (crops) in images.
Autonomous vehicles
For self-driving cars, YOLO helps identify traffic signs, pedestrians, and other road hazards with speed and precision, much like a human driver would.
Benefits of YOLO
There are numerous benefits that come with using algorithms like YOLO in AI models for object detection, particularly in speed and accuracy.
- Real-time applications: For industries where time management and quick reactivity are essential, like self-driving cars and security, YOLO is one of the best automated options for detecting objects in a picture or video.
- High levels of accuracy: With each new version of YOLO, the algorithm becomes more accurate at object detection with confidence in the output bounding boxes. Both the classifications and locations of objects in images are more accurate each time.
- Single-shot efficiency: Instead of waiting for images to be passed through several layers of a neural network, YOLO can process information in a single step to improve its overall efficiency and speed.
- Ability to assess images of different scales: YOLO is now able to process images with different aspect ratios and determine different sized objects within models that use anchor boxes as well as those without.
Top image recognition tools used for You Only Look Once
YOLO may only be used for a specific role in image recognition, object detection, but these tools can be added to workflows to complete many more tasks. Object detection is only one part of how images are processed using AI, with aspects like image restoration and scene reconstruction also possible with this software.
To be included in the image recognition category, platforms must:
- Provide a deep learning algorithm specifically for image recognition
- Connect with image data pools to learn a specific solution or function
- Consume the image data as an input and provide an output
- Provide image recognition capabilities to other applications, processes, or services
* Below are the top five leading image recognition software solutions from G2’s Summer 2024 Grid Report. Some reviews may be edited for clarity.
1. Google Cloud Vision API
Google Cloud Vision API is able to detect and classify multiple objects within images using a pre-trained algorithm that can be adapted into your own models. This software helps developers use the power of machine learning with industry-leading prediction accuracy.
What users like best:
“The most helpful thing I have experienced about this particular Vision API tool from Google is its detection feature integration in our Deep and Machine learning projects. Its API is helping us to detect any objects and label them with human understanding and form a machine learning model.”
- Google Cloud Vision API Review, Kunal D.
What users dislike:
“For low quality images, it sometimes gives the wrong answer as some food has the same color. It does not provide us the option to customize or train the model for our specific use case. The configuration part is complex.”
- Google Cloud Vision API Review, Badal O.
2. Gesture Recognition Toolkit
Gesture Recognition Toolkit is a cross-platform and open source machine learning library. It appeals to developers and AI engineers for its real-time gesture and image recognition options that integrate within their own algorithms and models.
What users like best:
“Its extensive set of algorithms and easy-to-use interface make it suitable for both beginners and advanced users.”
- Gesture Recognition Toolkit Review, Ram M.
What users dislike:
“Gesture Recognition Toolkit has occasional lag and a less smooth implementation process. Customer support response times could be faster.”
- Gesture Recognition Toolkit Review, Civic V.
3. SuperAnnotate
SuperAnnotate is a platform for building, fine-tuning, and managing your AI models with the highest quality, industry-leading training data. Advanced annotation technology and quality assurance tools enable you to build successful machine learning models and high-level datasets.
What users like best:
“I was looking for a tool to annotate biological images. After trying many tools, I found two of the best platforms for myself. One of them is Superannotate. These platforms had the widest set of annotation tools, including exactly the ones I needed. The tools are convenient to use.”
- SuperAnnotate Review, Artem M.
What users dislike:
“We have had some issues with custom workflows that the team implemented for specific projects on their platform. For certain custom workflows, we noticed that the analytics tool was misreporting the time taken for annotation.”
- SuperAnnotate Review, Rohan K.
4. Syte
Syte is the world’s first AI-powered product discovery platform helping both consumers and retailers connect with products. Camera search, personalization, and in-store tools like image recognition make for an instant and intuitive experience for shoppers.
What users like best:
“The team consistently offers valuable insights and alternatives to enhance the functionality and effectiveness of the Shop Similar Tool. Working with Syte facilitates the achievement of our site's specific KPIs.”
- Syte Review, Gabriella M.
What users dislike:
“There was some difficulty in enabling different accounts to the analytics dashboard. It would be nice to have no restrictions on these logins (different users should be able to access it).”
- Syte Review, Antonio R.
5. Dataloop
Dataloop is an AI development platform that allows businesses to build their own AI applications easily and with intuitive datasets. Tools within the software enable teams to optimize image annotation, model selection, and deployments of models for wide scale application.
What users like best:
“Dataloop also has a huge number of features that makes it convenient for many users of different projects. After each update there are instructions provided that explain the changes hence making it easy to implement them.”
- Dataloop Review, Mzamil J.
What users dislike:
“I have had challenges with some steep learning curves, infrastructure dependency, and customization limitations. These have in a way limited me in its usage.”
- Dataloop Review, Dennis R.

Start working with AI because YOLO!
In less than a decade, YOLO has made significant progress and become the go-to method of object detection for many industries. Thanks to its efficient and accurate approach to image recognition, it’s ideal for real-time needs as you explore the world of AI.
Learn more about artificial neural networks and how models are designed to mimic the human brain.
Edited by Monishka Agrawal

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.

