
Outages are unforgiving and happen all too frequently.
When they do, it's typically in the most unexpected moments. Maybe someone trips over a power cord, a network hiccup occurs, or the engineers move a disk and it gets corrupted.
Whatever happens, the outage hits, and we scramble to analyze what went wrong and get the servers back up as soon as possible.
Uptime is king. Increasing service downtime can negatively impact revenue, brand trust, data loss, and search rankings.
One way to handle sudden failure is to use a standby or failover component. Failover provides the means to respond proactively rather than reactively when unexpected outages occur.
With organizations moving toward business continuity in the cloud with disaster recovery as a service (DRaaS) software, it's imperative to understand how failover supports disaster recovery (DR) strategies and business continuity plans.
What is failover?
Failover is a backup operational mode in which a secondary system assumes the functions of the primary system when the latter becomes unavailable. The backup unit activates automatically and seamlessly, with little or no service interruption to users. Failover is usually employed for critical and fault-tolerant systems.
Failover is an integral part of DRaaS for business continuity in the cloud. The DRaaS software supplies this failover capability by providing a quick transfer of the workload if a service goes down.
Failover is implemented in mission-critical systems where data integrity and uptime are vital. In case of failure, an alternative system or solution is immediately ready to take over with little interruption to regular operation.
In short, failover is critical to keep you online and running. For example, during a primary data center failure, failover must transfer control of the mission-critical systems to the secondary data center with minimal disruption to services or loss of data.
Failover can occur in any part of a system:
- A hardware or software trigger on a personal computer or mobile device can safeguard the device when a component, such as a CPU or a battery cell, fails.
- Failover can apply to any individual network component or a system of components, such as a connecting channel, storage device, or web server, inside a network.
- Failover allows many local or cloud-based servers to keep a constant and secure connection with little or no service interruption while using a hosted database or web application.
Businesses establish redundancy in an unexpected failure by using a backup computer, system, or server that is always ready to transition into action automatically.
System designers implement failover functionality in servers, backend database support, or networks that require consistent availability and excellent dependability. Failover can:
- Safeguard your database during maintenance or a system outage. For example, if the primary server on-site goes down due to hardware failure, the backup server (on-site or in the cloud) can quickly take over hosting tasks with no administrative intervention.
- It can be tailored to your specific hardware and network setups. While managing a database, an admin can employ not just an A or B system of two servers running in parallel to safeguard each other but also a cloud server to provide comprehensive on-site troubleshooting, maintenance, and patching, all without affecting connectivity.
- Allow maintenance operations to run automatically without monitoring. An automatic switchover during periodic software upgrades provides seamless protection against cyber security hazards.
Did you know? A switchover is essentially the same as a failover; however, unlike a failover, it isn't automated and requires human interaction. Automated failover solutions protect most systems.
Why is failover important?
Merely tolerating or enduring downtime or outages is not good enough in today's competitive global marketplace. Thanks to failover and its technologies, customers can be confident they can rely on a secure connection without unexpected disruptions.
Failover integration can be an unwanted, expensive burden, but it's a vital insurance policy that ensures safety and security.
So, what is the primary reason a company has a failover system? The primary goal of failover is to prevent or reduce total system failure. Failover is an essential component of every company's DR plan. If the network architecture is appropriately set up, failover and failback will provide complete protection against most, if not all, service disruptions.
Any legitimate hiccups are mainly caused by the amount of the data switch, the available bandwidth, and how data is moved, mirrored, or copied to the second site. A systems engineer's priority should be reducing data transfer while enhancing sync quality between two sites.
After ensuring data transmission quality, the next issue is determining how to trigger failover while minimizing change-over time.
IT admins can also trigger a failover to ease the maintenance and upgrade of the primary system. This is known as a planned failover.
Quer aprender mais sobre Soluções de Recuperação de Desastres como Serviço (DRaaS)? Explore os produtos de Recuperação de Desastres como Serviço (DRaaS).
How does failover work?
Failover involves data restoration, application settings, and infrastructure support to a standby system component. For the end-user, the operation is seamless. Normal functioning continues despite the unavoidable disruptions induced by equipment failures because of the capacity for automated failover.
A failover system requires a direct link to the primary system to work successfully. This is known as a "heartbeat.” The heartbeat sends a pulse from the primary system to the failover system every few minutes. The failover solution will remain inactive as long as the pulse remains steady.
A heartbeat system is common in failover automation. In its most basic form, this method links two sites either physically via a cable or wirelessly over a network. When the regularity of the heartbeat link is disrupted, the failover system will activate and take over all of the primary system's functions. You can typically design your failover solutions to immediately alert your IT staff of a failure so they may work on restoring the primary system as quickly as feasible.
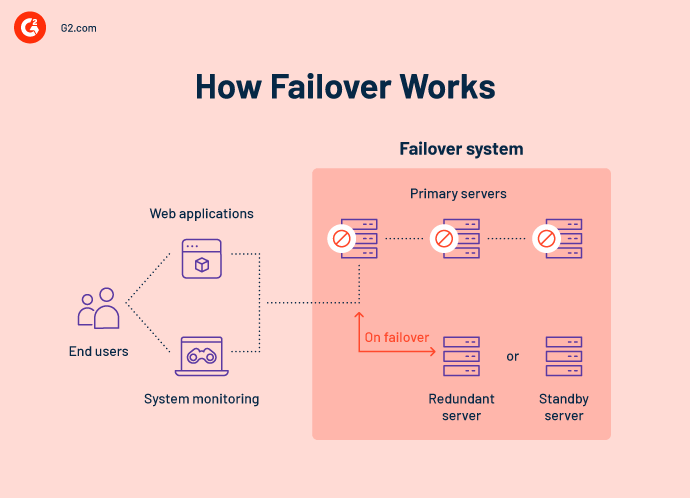
Based on the complexity of the service, a system may even have a third site running the fundamental components necessary to avoid downtime when switching. Multiple pathways, redundant components, and remote or cloud-based support provide a safe and always-connected path.
Virtualization replicates a computer environment by running host software on a VM. Therefore, the failover mechanism can be hardware-agnostic.
This procedure is usually carried out by a particular piece of software or hardware that enables this complex function. The top solutions offer automation and orchestration to ease recovery processes. These systems can also restore data from moments rather than hours or even days ago.
The integrity of the service is critical in minimizing downtime during failover. You'll need a DRaaS solution that knows your services and can restore them as a whole (rather than simply the components), resulting in a speedier return to regular IT operations.
What is a failover cluster?
A failover cluster is a collection of computer servers that work together to offer continuous availability (CA), failure tolerance (FT), or high availability (HA). Companies can build failover cluster network topologies entirely on physical hardware or incorporate virtual machines (VMs).
When one of the servers in a failover cluster breaks down, the failover mechanism is triggered. This reduces downtime by instantly transferring the workload of the malfunctioning element to another node in the cluster.
Continuous availability vs. failure tolerance vs. high availability
- Continuous availability is proactive. It emphasizes redundancy, fault detection, and error prevention. Such systems enable maintenance planning and updates during regular business hours without disrupting service.
- A fault-tolerant system has no service interruption but costs slightly more. It relies on dedicated hardware that detects a failure and instantly switches to a redundant hardware component. Although the transition seems smooth and provides continuous service, a significant price is paid for hardware cost and performance. This is because the redundant components don't execute any processing. More crucially, the FT paradigm ignores software errors, the most prevalent cause of downtime.
- A high-availability system (HA) causes minimum service interruption. HA combines software with industry-standard hardware to reduce downtime by restoring services when systems fail. Such systems are an excellent solution for services that must be quickly restored and withstand a short disruption during failure.
The primary purpose of a failover cluster is to provide either HA or CA for applications and services. CA clusters, often known as fault-tolerant clusters, reduce downtime when a primary system crashes, letting end-users continue accessing services and applications without interruption.
On the other hand, HA clusters provide automated recovery, little downtime, and zero data loss despite the risk of a slight disruption in operation. Most failover cluster solutions provide failover cluster management tools that enable administrators to control the process.
A cluster is generally two or more servers or nodes that are commonly linked programmatically and physically using cables. Some failover systems use additional clustering technologies, such as load balancing, parallel or concurrent processing, and storage solutions.
What is failover testing?
Failover testing confirms a system's ability to dedicate adequate resources to recovery following a system failure. In other words, failover testing assesses system failover capacity. The test will verify whether the system can manage extra resources and migrate activities to backup systems in the case of an unexpected termination or failure.
For example, failover and recovery testing verify the system's capacity to manage and power an additional CPU or many servers once it reaches a performance threshold that is frequently exceeded during significant failures. This underlines the critical link between failover testing, resilience, and security.
Failover testing is the process of simulating a failure in a primary server or system to evaluate the effectiveness of its failover mechanisms. Key aspects include:
- Purpose: To verify that backup systems can take over seamlessly during unexpected failures.
- Scenarios: Involves testing various failure scenarios like server crashes or network outages.
- Automated vs. manual: This can be done manually or with automated tools.
- Recovery time objective (RTO): Measures how quickly the system recovers
- Data integrity: Ensures that data remains intact during the failover process.
Types of failover configurations
The failover system technique uses existing clustering technologies to enable redundant executions, boosting the reliability and accessibility of IT resources.
There are two basic configurations for high-availability failover systems:active-active and active-passive. Although both implementation techniques improve dependability, they achieve failover in different ways.
1. Active-active configuration
An active-active high availability configuration typically consists of at least two nodes that are actively and concurrently executing the same kind of service. The active-active cluster performs load balancing by distributing workloads uniformly across all nodes, limiting any one node from overloading. As more nodes are available, response and throughput times improve.
Individual node setups and specifications should be identical to ensure the HA cluster runs smoothly and achieves redundancy. Load balancers allocate users to cluster nodes based on an algorithm. For instance, a round-robin algorithm evenly distributes users to servers based on when they join.
The usage of both nodes is split about 50/50, even though each node can manage the whole load independently. However, if one active-active configuration node routinely handles more than half of the load, node loss might cause performance to decrease.
Since both pathways are active, outage time during a failure is nearly negligible with an active-active HA system.
2. Active-passive configuration
In an active-passive configuration, also known as an active standby setup, there are at least two nodes, but not all are active. In a two-node configuration, the first node is operational, and the second node stays passive or on standby as the failover system.
This standby operational state can be backed up if the live primary node fails. On the other hand, users only connect to the active server until there is a failure. The inactive node is triggered to take over processing from an offline IT resource, and the related workload is routed to the secondary node, which takes over the operation.
Outage time is longer in an active-passive setup because the system must move from one node to another.
Failover vs. failback
Failover and failback are business continuity elements that enable regular digital operations to continue even if the primary production site is unavailable. Consider failover and failback procedures vital to a solid disaster recovery framework.
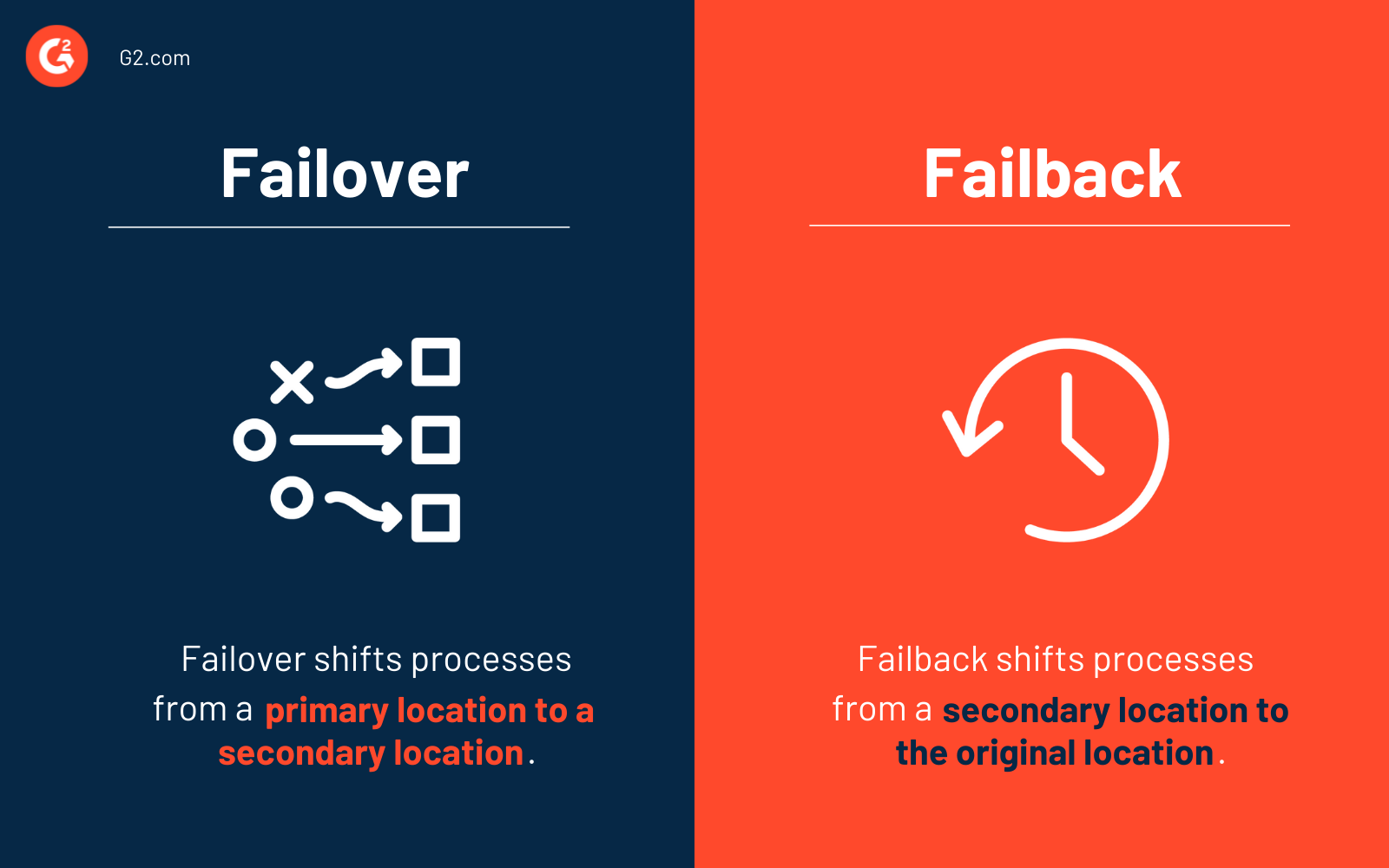
The failover process shifts production from the primary site to a secondary location. This recovery site typically contains a replicated copy of all of your primary production site's systems and data. During a failover, all updates are stored virtually.
Failback is a business continuity measure deployed when the primary production site is back up and operating after a disaster (or a scheduled event) is addressed. Production is restored to its old (or new) site during a failback, and any modifications recorded in virtual storage are synced.
Benefits of failover
For web-centric companies, service uptime is mission-critical since it impacts all operations. From organizational growth to customer retention and relationships, high availability is the essential criterion that companies cannot ignore. Benefits of failover systems include:
- Downtime protection: Implementing effective failover systems for mission-critical components of an organization's IT stack should significantly decrease downtime caused by service outages. If even one of the critical systems' components fails, it will prevent the proper operation of every component that interacts with it.
- Prevents revenue loss: If a vital business tool, such as your payment processing service, is unavailable for a long time, your organization's profitability will suffer. Since consumer actions are volatile, even one bad encounter can make customers permanently stop using your company.
Challenges of failover
Too often, failover is an afterthought or a last resort. However, by planning and testing failover procedures upfront, IT managers can prevent downtime and achieve consistent levels of service quality, especially when the unexpected happens.
A well-oiled failover process does come with high costs and can increase the likelihood of human error in the event of failures. However, implementing effective procedures may reduce the risk of loss in critical systems and minimize potential interruptions to service quality.
Even though failover looks like a savior in all its glory, implementing a failover strategy comes with significant challenges.
Increased cost
Setting up, maintaining, and monitoring a reliable, protected failover strategy is expensive. This is especially true if you want to ensure that each component of a complex, interconnected landscape has its unique failover mechanism.
To build dependable failover systems that function automatically with little downtime, you must invest money in high-bandwidth systems that can handle synchronous data exchanges. Most of the overall line item expenses for failover systems can be attributed to relying on third-party expertise to install and administer the systems.
Lengthy system management and quality assurance (QA) processes
A failover system needs the same maintenance and QA validation as primary systems to secure your organization's technology effectively. Running your primary and failover systems on separate versions negates having identical, synched systems in the first place, requiring more effort during tight maintenance periods.
You must also ensure that your failover systems can frequently interact with and engage with your environment's various components. These validations can substantially increase your IT staff's time allotted for testing and QA.
Failover use cases
Failover can occur in any part of a system, including a computer, a network, a storage device, or a web server. Here are some ways failover can help organizations create resilient infrastructure.
- Application server failover safeguards numerous servers that execute applications. These failover servers should ideally run on separate hosts and should all have distinct domain names.
- Domain name system (DNS) failover ensures network services or websites remain available during an outage. It generates a DNS record for a system that includes two or more IP addresses or failover connections. This allows users to reroute traffic from a failing system towards a live, redundant site.
- Dynamic host configuration protocol (DHCP) failover deploys two or more DHCP servers to handle the same pool of addresses. This allows each DHCP server to back up the other in the event of a network loss. They share the responsibility of lease assignment for that group at all times.
- SQL server failover removes any potential single point of failure by employing shared data storage and numerous network connections through a network-attached storage (NAS).
Failover gracefully
While failover integration can be expensive, consider the enormous cost of downtime. Think of failover as an essential safety and security insurance policy.
Failover should be a key component of your disaster recovery strategy. Your priority should be limiting data transfers to avoid bottlenecks while maintaining high-quality sync between the primary and backup systems from a systems engineering approach.
Discover how to create a robust disaster recovery plan that safeguards your operations and protects your valuable assets.
This article was originally published in 2022. It has been updated with new information.

Keerthi Rangan
Keerthi Rangan is a Senior SEO Specialist with a sharp focus on the IT management software market. Formerly a Content Marketing Specialist at G2, Keerthi crafts content that not only simplifies complex IT concepts but also guides organizations toward transformative software solutions. With a background in Python development, she brings a unique blend of technical expertise and strategic insight to her work. Her interests span network automation, blockchain, infrastructure as code (IaC), SaaS, and beyond—always exploring how technology reshapes businesses and how people work. Keerthi’s approach is thoughtful and driven by a quiet curiosity, always seeking the deeper connections between technology, strategy, and growth.


