



Suponha que você gerencie uma livraria online de grande porte. Ela está sempre aberta. A cada minuto ou segundo, clientes fazem e pagam por pedidos. Seu site precisa executar rapidamente inúmeras transações usando dados modestos, como IDs de usuários, números de cartões de pagamento e informações de pedidos.
Além de realizar tarefas do dia a dia, você também precisa avaliar seu desempenho. Por exemplo, você analisa as vendas de um livro ou autor específico do mês anterior para decidir se deve encomendar mais para este mês. Isso envolve a coleta de dados transacionais e a transferência deles de um banco de dados que suporta transações para outro sistema que gerencia grandes quantidades de dados. E, como é comum, os dados precisam ser transformados antes de serem carregados em outro sistema de armazenamento.
Apenas após essas ações você pode examinar os dados com software dedicado. Mas como você move os dados? Se você não sabe a resposta, provavelmente precisa de uma infraestrutura de software melhor, como soluções de troca de dados, ferramentas de extração, transformação e carregamento (ETL) ou soluções DataOps.
Você provavelmente precisa aprender o que um pipeline de dados pode fazer por você e seu negócio. Você provavelmente precisa continuar lendo.
O que é um pipeline de dados?
Um pipeline de dados é um processo que envolve a ingestão de dados brutos de várias fontes de dados e, em seguida, a transferência para um repositório de dados, como um data lake ou data warehouse, para análise.
Um pipeline de dados é um conjunto de etapas para o processamento de dados. Se os dados ainda precisam ser importados para a plataforma de dados, eles são ingeridos no início do pipeline. Uma sucessão de etapas segue, cada uma produzindo uma saída que serve como entrada para a etapa seguinte. Isso continua até que todo o pipeline seja construído. Etapas independentes podem coincidir em alguns casos.
Componentes do pipeline de dados
Antes de mergulharmos no funcionamento interno dos pipelines de dados, é essencial entender seus componentes.
- A origem é o ponto de entrada para dados de todas as fontes de dados no pipeline. A maioria dos pipelines se origina de aplicativos de processamento transacional, interfaces de programação de aplicativos (APIs), ou sensores de dispositivos da Internet das Coisas (IoT) ou sistemas de armazenamento, como data warehouses ou data lakes.
- O destino é o último lugar para onde os dados vão. O caso de uso determina o destino final.
- Fluxo de dados é o transporte de dados da origem para o destino e as alterações feitas neles. ETL é uma das metodologias de fluxo de dados mais utilizadas.
- Armazenamento refere-se a sistemas que mantêm dados em várias etapas enquanto eles se movem pelo pipeline.
- Processamento compreende todas as atividades e etapas envolvidas no consumo, armazenamento, alteração e colocação de dados. Embora o processamento de dados esteja relacionado ao fluxo de dados, esta etapa se concentra na implementação.
- Fluxo de trabalho especifica uma série de processos e suas dependências entre si.
- Monitoramento garante que o pipeline e suas etapas funcionem corretamente e executem as funções necessárias.
- Tecnologia refere-se à infraestrutura e ferramentas que suportam transmissão de dados, processamento, armazenamento, fluxo de trabalho e monitoramento.
Quer aprender mais sobre Ferramentas ETL? Explore os produtos de Ferramentas ETL.
Como funciona o pipeline de dados?
Os dados são normalmente processados antes de fluírem para um repositório. Isso começa com a preparação dos dados, onde os dados são limpos e enriquecidos, seguido pela transformação dos dados para filtragem, mascaramento e agregação de dados para sua integração e uniformidade. Isso é especialmente significativo quando o destino final do conjunto de dados é um banco de dados relacional. Bancos de dados relacionais têm um esquema predefinido que deve ser alinhado para corresponder às colunas e tipos de dados para atualizar os dados antigos com os novos.
Imagine que você está coletando informações sobre como as pessoas interagem com sua marca. Isso pode incluir sua localização, dispositivo, gravações de sessão, compras e histórico de interação com o atendimento ao cliente. Em seguida, você coloca todas essas informações em um armazém para criar um perfil para cada consumidor.
Como o nome sugere, os pipelines de dados servem como o "tubo" para projetos de ciência de dados ou painéis de inteligência de negócios. Os dados vêm de várias fontes, incluindo APIs, linguagem de consulta estruturada (SQL) ou bancos de dados NoSQL; no entanto, nem sempre são adequados para uso instantâneo.
Cientistas ou engenheiros de dados geralmente realizam tarefas de preparação de dados. Eles formatam os dados para atender aos requisitos do caso de uso comercial. Uma combinação de análise exploratória de dados e necessidades comerciais estabelecidas geralmente decide o tipo de processamento de dados que um pipeline requer. Os dados podem ser mantidos e exibidos quando corretamente filtrados, combinados e resumidos.
Pipelines de dados bem organizados são a base para várias iniciativas, incluindo análise exploratória de dados, visualização e atividades de aprendizado de máquina (ML).
Tipos de pipelines de dados
Processamento em lote e pipelines de dados em tempo real são os dois tipos básicos de pipelines de dados.
Processamento em lote de dados
Como o nome indica, o processamento em lote carrega "lotes" de dados em um repositório em intervalos predeterminados, geralmente planejados durante horários de pico de negócios. Outros workloads não são incomodados, pois os trabalhos de processamento em lote geralmente operam com grandes quantidades de dados, o que poderia sobrecarregar todo o sistema. Quando não há uma necessidade urgente de examinar um conjunto de dados específico (por exemplo, contabilidade mensal), o processamento em lote é o melhor pipeline de dados. Está associado ao processo de integração de dados ETL.
ETL tem três etapas:
- Extrair: obter dados brutos de uma fonte, como um banco de dados, um arquivo XML ou uma plataforma em nuvem contendo dados para ferramentas de marketing, sistemas CRM ou sistemas transacionais.
- Transformar: alterar o formato ou estrutura do conjunto de dados para corresponder ao sistema de destino.
- Carregar: transferir o conjunto de dados para o sistema de destino, que pode ser um aplicativo ou um banco de dados, data lakehouse, data lake ou data warehouse.
Dados em tempo real de streaming
Ao contrário do processamento em lote, o streaming de dados em tempo real denota que os dados precisam ser continuamente atualizados. Aplicativos e sistemas de ponto de venda (PoS), por exemplo, exigem dados em tempo real para atualizar o inventário e o histórico de vendas de seus itens; isso permite que os comerciantes notifiquem os consumidores se um produto está em estoque. Uma única ação, como uma venda de produto, é referida como um "evento", e ocorrências relacionadas, como adicionar um item ao carrinho de compras, são geralmente agrupadas como um "tópico" ou "fluxo". Esses eventos são posteriormente roteados por meio de sistemas de mensagens ou corretores de mensagens, como Apache Kafka, um produto de código aberto.
Pipelines de dados de streaming oferecem menor latência do que sistemas em lote porque os eventos de dados são tratados imediatamente após ocorrerem. Ainda assim, são menos confiáveis do que sistemas em lote, pois mensagens podem ser perdidas inadvertidamente ou passar muito tempo na fila. Corretores de mensagens ajudam a resolver esse problema com reconhecimentos, o que significa que um consumidor verifica o processamento da mensagem para o corretor para que ela possa ser removida da fila.
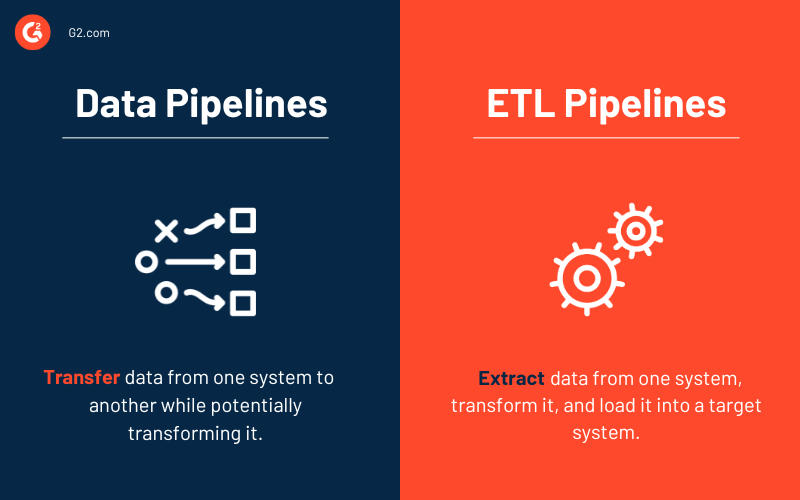
Pipelines de dados vs. pipelines ETL
Algumas palavras, como pipeline de dados e pipeline ETL, podem ser usadas de forma intercambiável. No entanto, considere um pipeline ETL um subtipo do pipeline de dados. Três características fundamentais separam os dois tipos de pipelines.
- Pipelines ETL seguem uma ordem predeterminada. Como a sigla sugere, eles extraem, convertem, carregam e armazenam dados em um repositório. Essa ordem não é necessária para todos os pipelines de dados. De fato, o surgimento de soluções nativas da nuvem aumentou o uso de pipelines ETL. A ingestão de dados ainda vem primeiro com esse tipo de pipeline, mas qualquer transformação vem depois que os dados foram carregados no data warehouse em nuvem.
- Embora o escopo dos pipelines de dados seja maior, pipelines ETL frequentemente envolvem processamento em lote. Eles também podem incluir processamento de fluxo.
- Finalmente, ao contrário dos pipelines ETL, os pipelines de dados como um todo podem não precisar sempre de transformações de dados. Quase todo pipeline de dados usa transformações para facilitar a análise.
Arquitetura do pipeline de dados
O design de um pipeline de dados é composto por três fases principais.
- Ingestão de dados. Os dados são adquiridos de várias fontes, incluindo dados estruturados e não estruturados. Essas fontes de dados brutos são comumente referidas como produtores, publicadores ou remetentes no contexto de dados de streaming. Enquanto as organizações podem optar por extrair dados apenas quando estão prontas para analisá-los, é melhor primeiro armazenar os dados brutos em um provedor de data warehouse em nuvem. Isso permite que a empresa emende quaisquer dados passados se precisar alterar operações de processamento de dados.
- Transformação de dados. Durante esta etapa, uma série de tarefas são realizadas para converter dados no formato exigido pelo repositório de dados de destino. Essas tarefas incorporam automação e governança para fluxos de trabalho repetidos, como relatórios de negócios, garantindo que os dados sejam constantemente limpos e convertidos. Um fluxo de dados, por exemplo, pode estar em formato de notação de objeto JavaScript (JSON) em camadas, e a etapa de transformação de dados tentará desenrolar esse JSON para extrair os campos essenciais para análise.
- Repositório de dados. Os dados transformados são posteriormente armazenados em um repositório e disponibilizados para várias partes interessadas. Os dados alterados são às vezes chamados de consumidores, assinantes ou receptores.
Benefícios dos pipelines de dados
As empresas tendem a aprender sobre pipelines de dados e como eles ajudam as empresas a economizar tempo e manter seus dados organizados quando estão crescendo ou procurando por melhores soluções. A seguir estão alguns benefícios dos pipelines de dados que as empresas podem achar atraentes.
- Qualidade dos dados refere-se à facilidade com que os usuários finais podem monitorar e acessar dados relevantes à medida que se movem da origem para o destino.
- Os pipelines permitem que os usuários gerem fluxos de dados iterativamente. Você pode pegar uma pequena fatia de dados da fonte de dados e apresentá-la ao usuário.
- Replicabilidade de padrões pode ser reutilizada e reaproveitada para novos fluxos de dados. Eles são uma rede de pipelines que gera um método de pensamento em que pipelines individuais são vistos como exemplos de padrões em um design maior.
Desafios com pipelines de dados
Construir um pipeline de dados bem arquitetado e de alto desempenho requer planejamento e design de vários aspectos do armazenamento de dados, como estrutura de dados, design de esquema, manuseio de alterações de esquema, otimização de armazenamento e escalonamento rápido para atender a aumentos inesperados no volume de dados de aplicativos. Isso geralmente exige o uso de uma técnica ETL para organizar a transformação de dados em várias fases. Você também deve garantir que os dados ingeridos sejam verificados quanto à qualidade ou perda de dados e que falhas de trabalho e exceções sejam monitoradas.
Abaixo estão alguns dos problemas mais comuns que surgem ao trabalhar com pipelines de dados.
- Aumento no volume de dados processados
- Alterações na estrutura dos dados de origem
- Dados de baixa qualidade
- Insuficiência de integridade dos dados nos dados de origem
- Duplicação de dados
- Atraso nos arquivos de dados de origem
- Falta de uma interface de desenvolvedor para testes
Casos de uso de pipelines de dados
O gerenciamento de dados está se tornando uma preocupação cada vez mais importante à medida que os dados extensos crescem. Embora os pipelines de dados sirvam a vários propósitos, a seguir estão três aplicações comerciais principais.
- Análise exploratória de dados (EDA) avalia e investiga conjuntos de dados e relata suas propriedades principais, geralmente usando abordagens de visualização de dados. Ajuda a determinar como modificar fontes de dados para obter as respostas necessárias, tornando mais fácil para os cientistas de dados descobrir padrões, detectar anomalias, testar hipóteses e validar suposições.
- Visualizações de dados usam visuais populares para descrever dados: gráficos, diagramas, infográficos e animações. Esses visuais de informações explicam relações de dados complexas e insights baseados em dados de uma maneira fácil de entender.
- Aprendizado de máquina é um subcampo da inteligência artificial (IA) e ciência da computação que usa dados e algoritmos para imitar como as pessoas aprendem, melhorando gradualmente sua precisão. Algoritmos são ensinados a gerar classificações ou previsões usando abordagens estatísticas, revelando insights cruciais em iniciativas de mineração de dados.
Exemplos reais de pipelines de dados
A seguir estão alguns exemplos de pipelines de dados da vida real de empresas que criaram pipelines modernos para sua aplicação.
- Uber precisa de dados em tempo real para implementar preços dinâmicos, calcular o tempo de chegada mais provável e antecipar a demanda e oferta. Eles implantam pipelines de streaming que ingerem dados atuais de aplicativos de motoristas e passageiros usando tecnologias como Apache Flink. Esses dados em tempo real são incorporados em algoritmos de aprendizado de máquina, que fornecem previsões minuto a minuto.
- Hewlett Packard Enterprise esperava melhorar a experiência do cliente com sua capacidade de manutenção preditiva. Eles construíram um pipeline de dados eficiente com motores de streaming como Akka Streams, Apache Spark e Apache Kafka.
- Dollar Shave Club precisava de dados em tempo real para interagir com cada consumidor separadamente. Após alimentar informações em seu sistema de recomendação, o programa escolheu quais produtos promover para inclusão em um e-mail mensal endereçado a clientes individuais. Eles criaram um pipeline de dados automatizado usando Apache Spark para essa prática.
Melhores práticas para pipelines de dados
Você pode evitar os perigos significativos de pipelines de dados mal construídos seguindo as práticas recomendadas descritas abaixo.
- Resolução de problemas simples: Ao remover dependências desnecessárias entre os componentes do pipeline de dados, você só precisa rastrear até o local da falha. Simplificar as coisas melhora a previsibilidade do pipeline de dados.
- Escalabilidade: À medida que workloads e volumes de dados crescem exponencialmente, um design ideal de pipeline de dados deve ser capaz de escalar e expandir.
- Visibilidade de ponta a ponta: Você pode garantir consistência e segurança proativa com monitoramento contínuo e inspeções de qualidade.
- Testes: Após ajustar com base nos testes de qualidade, você agora tem um conjunto de dados confiável para executar pelo pipeline. Depois de definir um conjunto de testes, você pode executá-lo em um ambiente de teste separado; em seguida, compará-lo com a versão de produção do seu pipeline de dados e a nova versão.
- Manutenibilidade: Procedimentos repetíveis e adesão rigorosa a protocolos suportam um pipeline de dados de longo prazo.
Ferramentas de pipeline de dados
Ferramentas de pipeline de dados suportam fluxo de dados, armazenamento, processamento, fluxo de trabalho e monitoramento. Muitos fatores influenciam sua seleção, incluindo tamanho e setor da empresa, quantidades de dados, casos de uso de dados, orçamento e necessidades de segurança.
A seguir estão grupos de soluções comumente usados para construir pipelines de dados.
Ferramentas ETL
Ferramentas ETL incluem soluções de preparação de dados e integração de dados. Elas são usadas principalmente para mover dados entre bancos de dados. Elas também replicam dados, que são então armazenados em sistemas de gerenciamento de banco de dados e data warehouses.
Top 5 ferramentas ETL:
* Acima estão as cinco principais soluções ETL do Relatório Grid® de Verão de 2023 da G2.
Plataformas DataOps
Plataformas DataOps orquestram pessoas, processos e tecnologia para entregar um pipeline de dados confiável aos seus usuários. Esses sistemas integram todos os aspectos da criação e operações de processos de dados.
Top 5 plataformas DataOps:
* Acima estão as cinco principais soluções DataOps do Relatório Grid® de Verão de 2023 da G2.
Soluções de troca de dados
Empresas usam ferramentas de troca de dados durante a aquisição para enviar, adquirir ou enriquecer dados sem alterar seu propósito principal. Os dados são transferidos para que possam ser facilmente ingeridos por um sistema receptor, muitas vezes normalizando-os completamente.
41,8%
das pequenas empresas no setor de TI usam soluções de troca de dados.
Fonte: dados de avaliação de clientes da G2
Várias soluções de dados podem trabalhar com trocas de dados, incluindo plataformas de gerenciamento de dados (DMPs), software de mapeamento de dados ao mover dados adquiridos para armazenamento, e software de visualização de dados para converter dados em painéis e gráficos legíveis.
Top 5 ferramentas de software de troca de dados:
* Acima estão as cinco principais soluções de troca de dados do Relatório Grid® de Verão de 2023 da G2.
Outros grupos de soluções para pipelines de dados incluem o seguinte.
- Data warehouses são repositórios centrais para armazenar dados convertidos para um propósito específico. Todas as principais soluções de data warehouse agora transmitem carregamento de dados e permitem operações ETL e transmissor de localizador de emergência (ELT).
- Os usuários armazenam dados brutos em data lakes até que precisem deles para análises de dados. As empresas desenvolvem pipelines de Big Data baseados em ELT para iniciativas de aprendizado de máquina usando data lakes.
- As empresas podem utilizar agendadores de fluxo de trabalho em lote para declarar programaticamente fluxos de trabalho como tarefas com dependências e automatizar essas operações.
- Software de streaming de dados em tempo real processa dados continuamente criados por fontes como sensores mecânicos, dispositivos IoT e Internet das coisas médicas (IoMT) ou sistemas de transação.
- Ferramentas de Big Data incluem soluções de streaming de dados e outras tecnologias que permitem o fluxo de dados de ponta a ponta.

Dados detalhados datam profundamente
Antigamente, volumes de dados de várias fontes eram armazenados em silos separados que não podiam ser acessados, entendidos ou analisados em trânsito. Para piorar as coisas, os dados estavam longe de serem em tempo real.
Mas hoje? À medida que a quantidade de fontes de dados cresce, a taxa na qual as informações atravessam organizações e setores inteiros é mais rápida do que nunca. Os pipelines de dados são o esqueleto dos sistemas digitais. Eles transferem, transformam e armazenam dados, fornecendo a empresas como a sua insights significativos. No entanto, os pipelines de dados devem ser atualizados para acompanhar o ritmo com a complexidade crescente e o número de conjuntos de dados.
A modernização requer tempo e esforço, mas pipelines de dados eficientes e contemporâneos capacitarão você e suas equipes a tomar decisões melhores e mais rápidas, dando a você uma vantagem competitiva.
Quer aprender mais sobre gerenciamento de dados? Aprenda como você pode comprar e vender dados de terceiros!

Samudyata Bhat
Samudyata Bhat is a Content Marketing Specialist at G2. With a Master's degree in digital marketing, she currently specializes her content around SaaS, hybrid cloud, network management, and IT infrastructure. She aspires to connect with present-day trends through data-driven analysis and experimentation and create effective and meaningful content. In her spare time, she can be found exploring unique cafes and trying different types of coffee.

