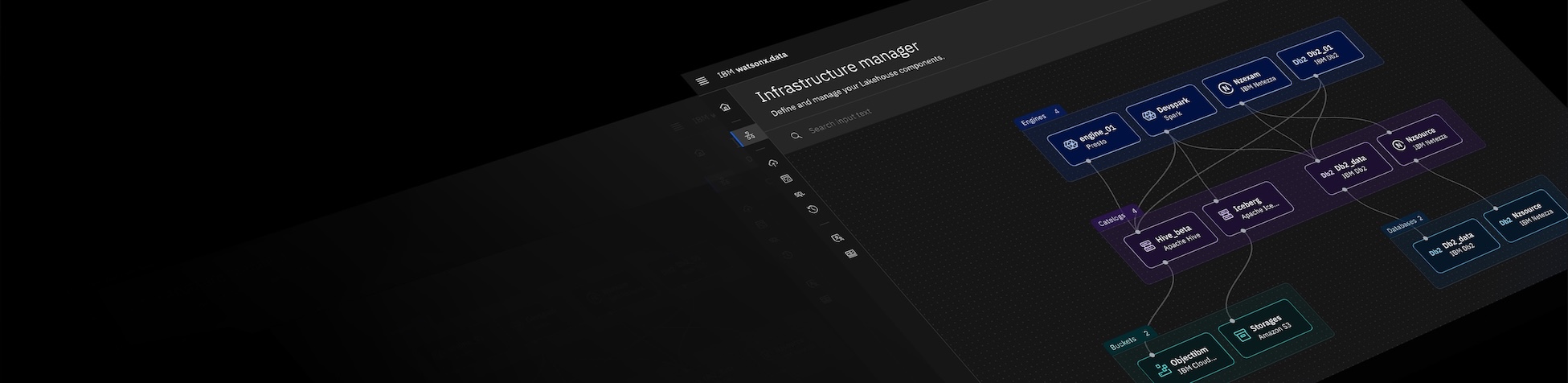




J'ai utilisé IBM watsonx.data dans plusieurs projets clients au cours des derniers mois, principalement pour des tâches lourdes en données où nous avions besoin d'une configuration de type "lakehouse". Ce que j'ai le plus apprécié, c'est que cela nous a permis de conserver les données dans le stockage d'objets tout en les interrogeant avec SQL, sans avoir besoin de tout déplacer dans un entrepôt traditionnel. Cela a réduit beaucoup de duplications de données inutiles.
Le support pour les formats ouverts comme Iceberg a été vraiment utile. Dans un projet, nous avons eu des changements de schéma en cours de route. Pouvoir gérer la version sans perturber les requêtes existantes nous a fait gagner du temps. Avis collecté par et hébergé sur G2.com.
La configuration initiale nous a pris un certain temps, surtout en ce qui concerne la configuration du stockage et des contrôles d'accès. Ce n'est pas exactement du plug-and-play, donc il y a une courbe d'apprentissage pour les équipes nouvelles aux architectures de lakehouse. Nous avons également dû examiner attentivement la documentation pour comprendre certaines étapes de configuration. Une fois configuré, cela a bien fonctionné. Cependant, l'intégration pourrait certainement être plus fluide. Avis collecté par et hébergé sur G2.com.






