
Vladimir N. Vapnik developed support vector machine (SVM) algorithms to tackle classification problems in the 1990s. These algorithms find an optimal hyperplane, which is a line in a 2D or a 3D plane, between two dataset categories to distinguish between them.
SVM eases the process of the machine learning (ML) algorithm to generalize new data while making accurate classification predictions.
Many image recognition software and text classification platforms use SVM to classify images or textual documents. But the reach of SVMs goes beyond these. After covering the fundamentals, let’s explore some of their broader uses.
What are support vector machines?
Support vector machines (SVMs) are supervised machine learning algorithms that come up with classification methods of objects in an n-dimensional space. The coordinates of these objects are usually called features.
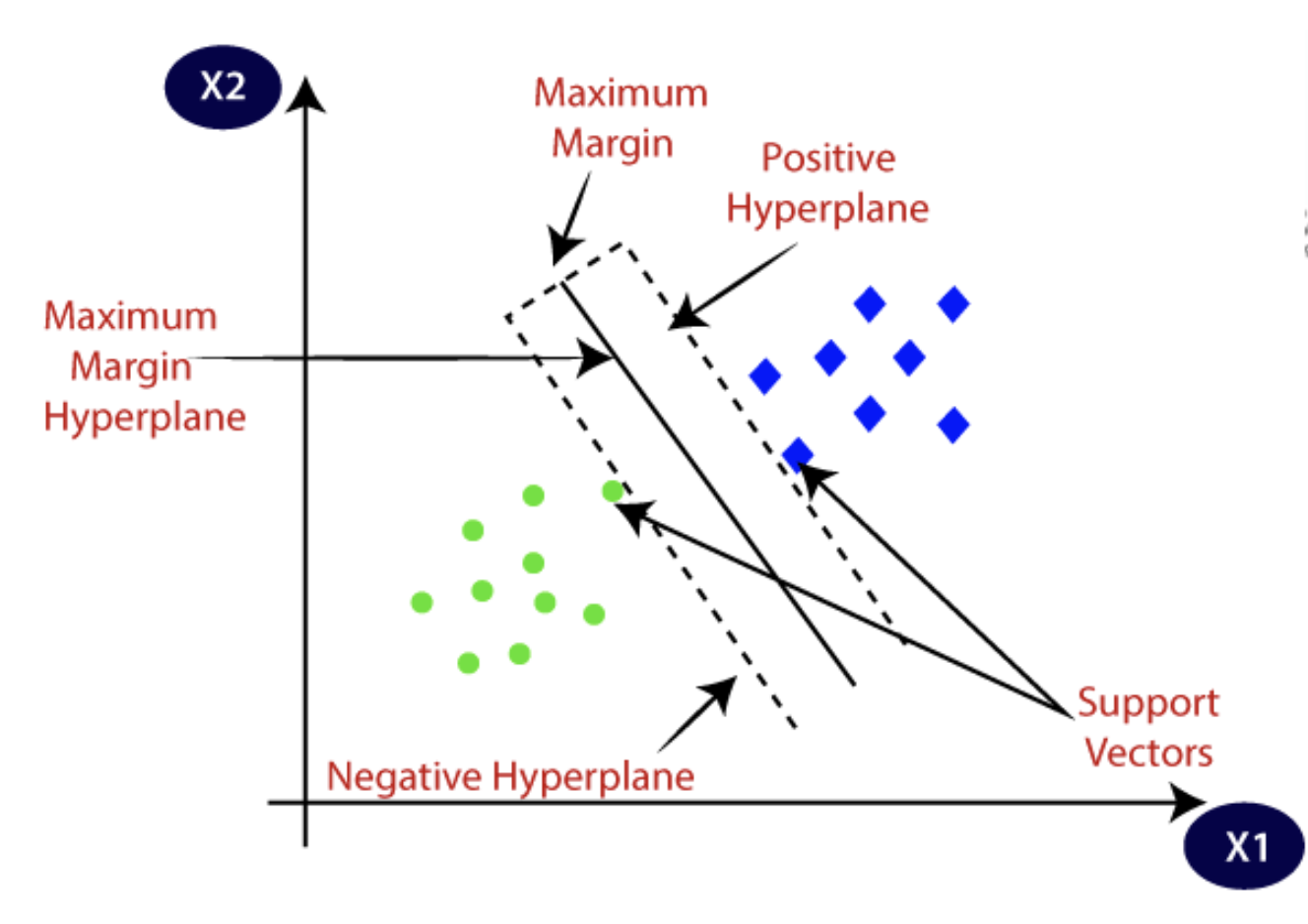
SVMs draw a hyperplane to separate two object categories so that all points from one object category are on one side of the hyperplane. The objective is to find the best plane, which maximizes the distance (or margin) between two points in either category. The points that fall on this margin are called support vectors. These support vectors are critical in defining the optimal hyperplane.
Understanding support vector machines in detail
SVM requires training on labeled points from specific categories to find the hyperplane, making it a supervised learning algorithm. The algorithm solves a convex optimization problem in the background to maximize the margin with each category point on the right side. Based on this training, it can assign a new category to an object.

Source: Visually Explained
Support vector machines are easy to understand, implement, use, and interpret. However, their simplicity doesn’t always benefit them. In some situations, it's impossible to separate two categories with a simple hyperplane. To solve this, the algorithm finds a hyperplane in the higher-dimensional space with a technique known as kernel trick and projects it back to the original space.
It is the kernel trick that allows you to perform these steps efficiently.
Vous voulez en savoir plus sur Logiciel de reconnaissance d'image ? Découvrez les produits Reconnaissance d'image.
What is a kernel trick?
In the real world, separating most datasets with a simple hyperplane is challenging since the boundary between two classes is rarely flat. This is where the kernel trick comes in. It allows SVM to handle non-linear decision boundaries efficiently without significantly altering the algorithm itself.
However, choosing this non-linear transformation is tricky. To get a sophisticated decision boundary, you need to increase the dimension of the output, which increases the computational requirements.
The kernel trick solves these two challenges in one shot. It’s based on an approach where the SVM algorithm doesn’t need to know whenever each point is mapped under nonlinear transformation. It can work with how each data point compares with others.
While applying the non-linear transformation, you take the inner product between F(x) and F(x) prime, known as the kernel function.
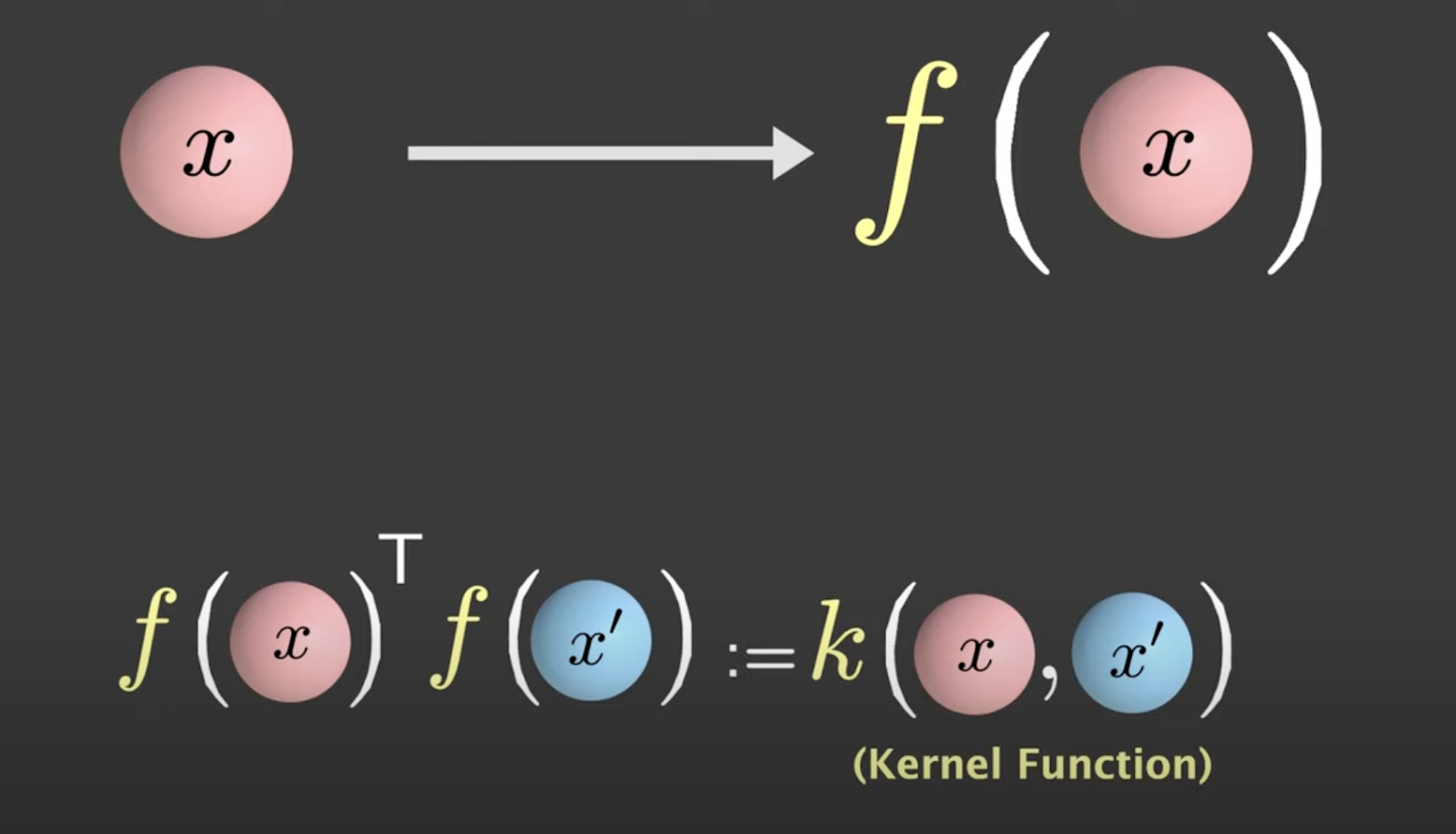
Source: Visually Explained
However, this linear kernel gives a decision boundary that may or may not be good enough to separate the data. In such cases, you go for a polynomial transformation corresponding to a polynomial kernel. This approach takes into account the original features of the data set as well as considers their interactions to get a more sophisticated, curved decision boundary.

Source: Visually Explained
The kernel trick is beneficial and feels like a video game cheat code. It’s easy to tweak and get creative with kernels.
Types of support vector machine classifiers
There are two types of SVM classified: linear and kernel.
1. Linear SVMs
Linear SVMs are when data doesn’t need to undergo any transformations and is linearly separable. A single straight line can easily segregate the datasets into categories or classes.
Source: Javatpoint
Since this data is linearly distinct, the algorithm applied is known as a linear SVM, and the classifier it produces is the SVM classifier. This algorithm is effective for both classification and regression analysis problems.
2. Non-linear or kernel SVMs
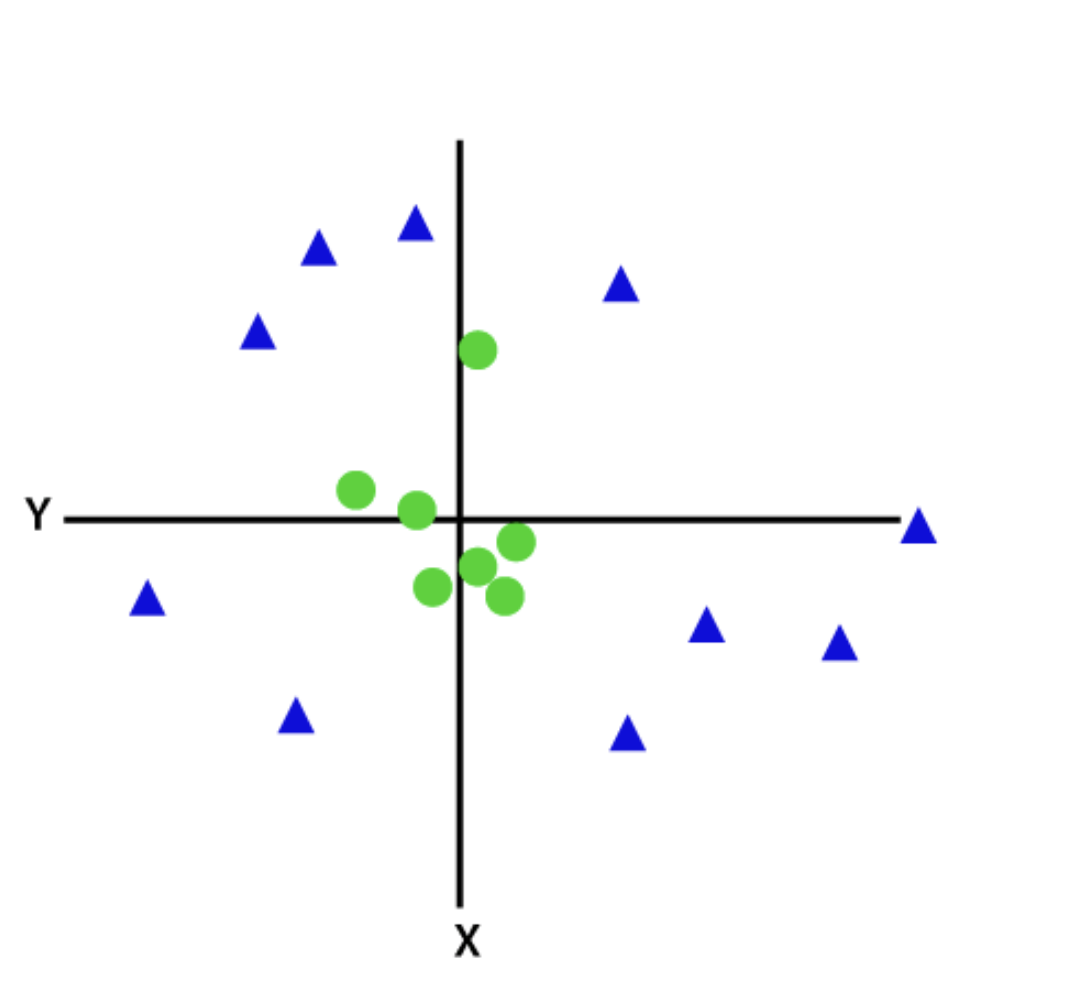
When data is not linearly separable by a straight line, a non-linear or Kernel SVM classifier is used. For non-linear data, the classification is performed by adding features into higher dimensions rather than relying on 2D space.
Source: Javatpoint
After transformation, adding a hyperplane that easily separates classes or categories becomes easy. These SVMs are usually used for optimization problems with several variables.
The key to non-linear SVMs is the kernel trick. By applying different kernel functions such as linear, polynomial, radial basis function (RDF), or sigmoid kernel, SVMs can handle a wide variety of data structures. The choice of kernel depends on the characteristics of the data and the problem being solved.
How does a support vector machine work?
Support vector machine algorithm aims to identify a hyperplane to separate data points from different classes. They were potentially designed for binary classification problems but evolved to solve multiclass problems.
Based on data characteristics, SVMs employ kernel functions to transform data features to higher dimensions, making it easier to add a hyperplane separating different classes of datasets. This occurs through the kernel trick technique, where data transformation is achieved efficiently and in a cost-effective manner.
To understand how SVM works, we must look into how an SVM classifier is built. It starts with spitting the data. Divide your data into a training set and a testing set. This will help you identify outliers or missing data. While not technically necessary, it's good practice.
Next, you can import an SVM module for any library. Scikit-learn is a popular Python library for support vector machines. It offers effective SVM implementation for classification and regression tasks. Start by training your samples on the classifier and predicting responses. Compare the test set and the predicted data to compare accuracy for performance evaluation.
There are other evaluation metrics you can use, like:
- F1-score computes how many times a model made a correct prediction across the entire dataset. It combines the precision and recall scores of a model.
- Precision score measures how often a machine learning model correctly predicts the positive class.
- Recall evaluates how often an ML model identifies true positives from all the actual positive samples in the dataset.
Then, you can tune the hyperparameters to improve an SVM model’s performance. You get the hyperparameters by iterating on different kernels, gamma values, and regularization, which helps you locate the most optimal combination.
Support vector machine applications
SVMs find applications in several fields. Let’s look at a few examples of SVMs applied to real-world problems.
- Ground surface strength estimation: Calculating soil liquefaction is critical in designing civil engineering structures, especially in zones that are prone to earthquakes. SVMs help predict whether or not liquefaction occurs in soil by creating models that include multiple variables for assessing ground strength.
- Geo-sounding problem: SVMs help track the planet’s layered structure. The regularization properties of the support vector formulation are applied to the geosounding inverse problem. Here, the results estimate the variables or parameters that produced them. The process involves linear functions and support vector algorithmic models separating electromagnetic data.
- Protein remote homology detection: SVM models use kernel functions to detect similarities in protein sequences based on the amino acid sequences. This helps categorize proteins into structural and functional parameters, which is important in computational biology.
- Facial detection and expression classification: SVMs classify facial structures from non-facial ones. These models analyze the pixels and classify the features into facial or non-facial characteristics. In the end, the process creates a square decision boundary around the facial structure based on the intensity of pixels.
- Text categorization and handwriting recognition: Here, each document carries a score compared with a threshold value, making it easy to classify it in the relevant category. To recognize handwriting, the SVM models are first trained with training data on handwriting, and then they segregate human and computer writing based on score.
- Steganography detection: SVMs help ensure that digital images are not contaminated or tampered with by anyone. It separates each pixel and stores them in different datasets that SVMs analyze later.
Solving classification problems with accuracy
Support vector machines help solve classification problems while making accurate predictions. These algorithms can easily handle linear and non-linear data, making them suitable for various applications, from text classification to image recognition.
Moreover, SVMs reduce overfitting, which happens when the model learns too much from the training data, affecting its performance on new data. They focus on important data points, called support vectors, helping them deliver reliable and accurate results.
Learn more about machine learning models and how to train them.
Edited by Monishka Agrawal

Sagar Joshi
Sagar Joshi is a former content marketing specialist at G2 in India. He is an engineer with a keen interest in data analytics and cybersecurity. He writes about topics related to them. You can find him reading books, learning a new language, or playing pool in his free time.

