
Be it B2B or B2C industry, the race to step up in artificial intelligence domain is bubbling on the surface with computer vision techniques like image annotation.As more brands decide to work with advanced machine learning models and train it on visuals and graphics, more accurate their image annotation process would be. Marking a change from traditional ML storage problems, data complexity and data incompatibility, image annotation relies on pre-trained image sets and effective model training to label images.
Brands have started implementing image annotation services via image recognition software to mimic human vision in products and build self-assist inventions like Tesla or Waymo. But, to get into the basics of image annotation, we need to come back to the drawing board first.
What is image annotation?
Image annotation divides an image or real-life scenario into specific blocks and labels and tags the objects within those blocks. Once all the objects are labeled, this image is used as a part of training dataset for the algorithm to classify and detect objects within newer and unseen images.
Once this is complete, the model in training processes the information so that it can replicate these annotations without human oversight moving forward. The labels give descriptive information about what’s happening in the image, helping the machine focus on the most important parts of the visual. This increases the accuracy and precision of future annotations.
Image annotations are considered to be the standard baseline for training AI models. It’s vital to get them right from the start because any errors made at this early stage will be replicated once the machine takes over processing.
Image annotation vs. image segmentation vs. image classification
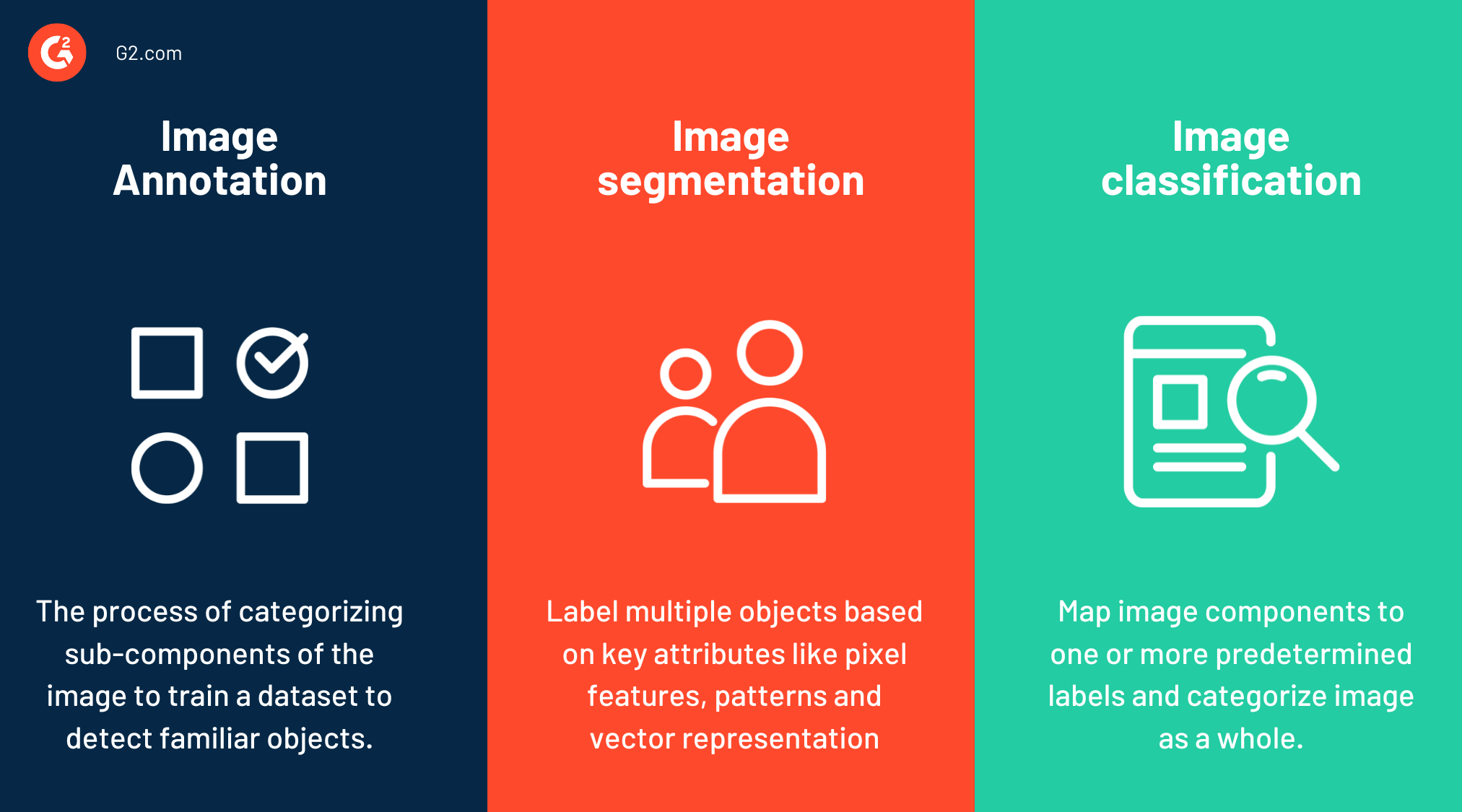
Image annotation looks at an overall image and creates labels based on what it sees within the visual, relying on the pre-trained datasets as references. It labels each pre-conceived object or element as a part of the training dataset or training pipeline so that the ML algorithm is certain during future predictions. Image annotation is used in object detection, vehicle perception, image processing, scene reconstruction and so on.
Image segmentation breaks images into separate sets of pixels or image segments to help the machine better understand what’s happening in the image. It analyzes region features, object pixels, vectors and color and intensity with bounding boxes and then predicts image components or outer characteristics of the image as a generically classified category. In image segmentation, models are trained to assess the data at a pixel level rather than a broader, scaled-back level.
Image classification is a type of pattern recognition in computer vision that analyzes posture, key nodal points, and vector or facial features to determine the category of an object. It creates a downsized version and studies patterns or common styles in the image. The image is then compared with a similar template from the underlying ML dataset to arrive at a particular conclusion. Image classification is a contextual form of object recognition and is used across fields of computer generated imagery, arts and humanity, security and surveillance and more.
Vous voulez en savoir plus sur Logiciel de reconnaissance d'image ? Découvrez les produits Reconnaissance d'image.
Image annotation types
There are four main types of image annotation, all working towards different levels of understanding when training the AI model. These are:
- Classification. This type of annotation takes a holistic view of the image and assigns a label to it based on the bigger picture. Identifying and categorizing the class of the image, rather than specific elements within the image, is an important starting point. The process can also be known as tagging. For example, an annotator could label an image as “kitchen” or “pizza” at this level.
- Object detection. This annotation type identifies the presence, location, and number of objects within the image and separately labels these. There could be multiples of the same object or different objects with different labels. Bounding boxes, where the object is encased in a digital box to be labeled, are the most common ways to denote the object boundaries and help train the machine for future identification. Medical CT and MRI scans are a more complex form of object detection, looking for indicators of anomalies in body scans.
- Semantic segmentation. This type of pixel-level segmentation identifies the boundaries between similar objects and labels them accordingly. The objects in the image are divided into clusters with their own labels, separating these groups out from the rest of the image.
- Instance segmentation. This is a more in-depth level of segmentation, where every instance of an object is separately identified, and the boundaries are marked. Even if similar objects are present in the image, each instance will be labeled separately rather than as a broader group, as semantic segmentation does.
- Panoptic segmentation: Panoptic segmentation combines semantic segmentation and instance segmentation. It outlines the class of every pixel in the image, drawing a fine line between individual objects (like humans or cars) or natural objects (like trees or sky) to accurately classify images. This unified approach makes it viable for bigger scale projects in automotive or robotic automation tasks.
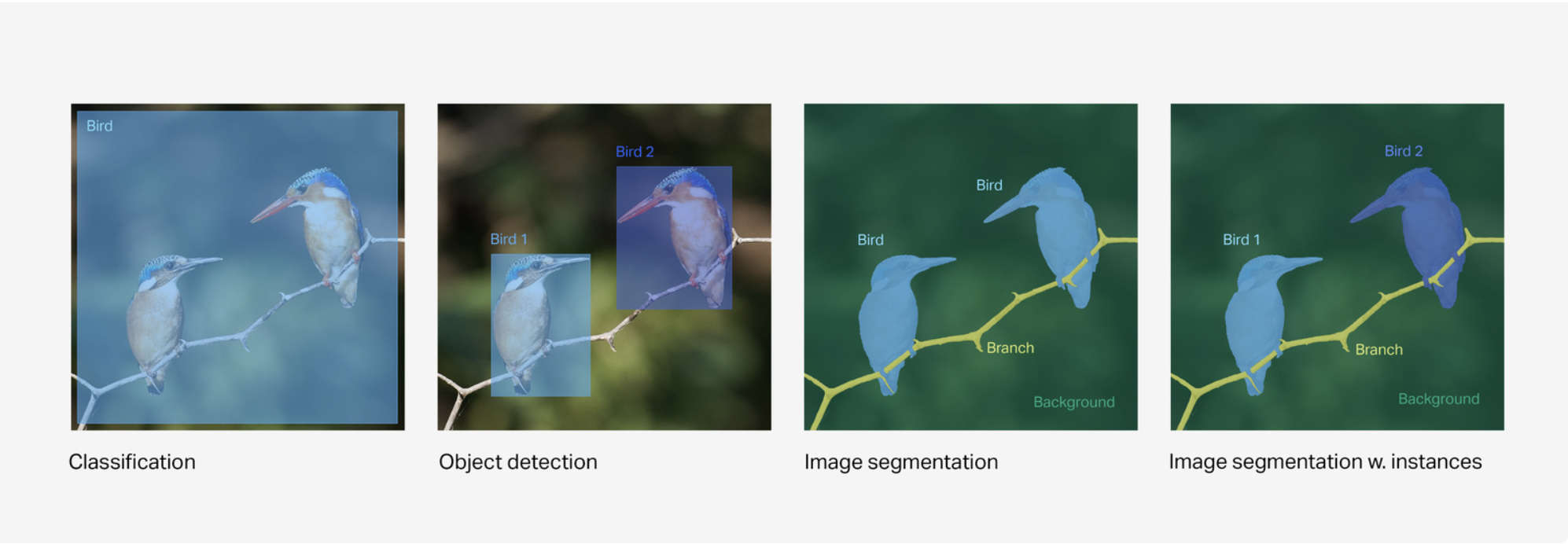
Source: LabelBox
How image annotation works
The type of annotation required, the quality of the data input, and the format in which the annotations need to be stored all impact how image annotation works. But, generally, even the most basic image annotations follow a similar process to the most complex training models.
1. Source high-quality input data
The most effectively trained machine learning models all started with high-quality data. Before inputting anything into the model, data should be cleaned and processed to ensure that any low-quality data isn’t skewing the training or impacting results. You can use your own datasets from information collected in-house, or you can buy public datasets to start training your model.
2. Determine what labels should be used
Depending on the type of image annotation you want, you’ll need to figure out which labeling categories are needed. For image classification, class numbers are sufficient as you’re only looking for an overall category rather than specific instances. However, with segmentation or object detection, you’ll need to be more granular in the labels you use to help the machine identify objects on a pixel level.
3. Create a class for each object
Most machine learning algorithms are built around data with a fixed number of classes rather than endless possibilities. Set up the number you want to use and their names early in the process to prevent duplicates later on, or similar objects being labeled under different names.
4. Annotate the image
This is where the work of labeling the image begins. Go through the visuals in your dataset carefully, annotating or tagging the images to the level you need. Always provide class labels for each object at the training stage to make your algorithm as accurate and precise as possible. When using object detection, make sure that boundary boxes or polygons are tight to image boundaries to keep data accurate.
5. Save the dataset and export it
The most popular way to save and export data is as a JSON or XML file type. But for deep learning machines, common objects in context dataset (COCO) file types can also be used to plug into another AI model later on without having to convert the file.
Image annotation benefits
As with any developing technology, AI will take time to become more accurate and help businesses complete their tasks efficiently. Rapid growth in this area has meant that AI image annotation brings numerous benefits.
- Building more accurate models: Correctly labeling data and thoroughly annotating the training data to the best of your abilities will improve the model’s accuracy moving forward. This allows you to do more in less time as you develop the algorithms within your machine.
- Cost-effective AI training: Getting the image annotation process right up front can save significant money and resources on AI training in the future. Clear labeling can prevent errors from being made in the training stage, which means less time being wasted correcting these once the machine learning algorithm takes over labeling without human supervision.
- Improved machine intelligence: Image annotation is the foundation for how visual AI machines understand and interact with the data they’re presented with. Numerous industries now use it to power complex machines, making image annotation a vital part of the training process.
- Versatility: Image annotation requires large computation datasets, which makes it versatile and fast calculative algorithm for diverse tasks like facial recognition, AI data labeling, object detection and more. It can accept heterogenous input like credit card numbers, surveillance data or pan tilt zoom (PTZ) camera data.
- Facilitates supervised learning: The more image annotation algorithm is exposed to unseen images, the better it facilitates supervised learning to label output data. It self-learns and builds on new knowledge and leverages it to retrain the algorithm and adjust probability classifications if encountered with newer layouts or features.
- Boosts generalization: Image annotation models also generalize certain elements so that they figure out whether they are dealing with a real-life scenario or a still life scenario. By studying the background features and choosing human annotation, these tools improve their detection and classification processes.
Image annotation challenges
Though image annotation proves resourceful to understand and intercept visual data, it doesn't always showcase accurate predictions.
- Time consuming: Because image datasets are first labeled with data labeling service or a human annotator, the process of image labeling consumes a lot of extra time. Annotating large datasets is a time, resource and labor intensive process and leads to misclassifications or errors.
- High cost: Image annotation services are costly because of their prime use case of outlining image categories. Given the prominence of these tools in computer vision and object detection products, investing in it would chip away majority of your AI budget.
- Subjectivity: During the process, the algorithm may mistakenly categorize a new component with the same label as that of training dataset, whereas the component might be different in context. The tool doesn't factor in the subjectivity or scenario of an image component and passes on old labels.
- Scalability issues: Labeling images with image annotation tools is not scalable to the entire data of the company. The ML model might not comply with the nature or data environment of different datasets.
- Requirement for expertise: Working with an image annotation tool requires expert views and ideas of a machine learning developer or data scientist. Other than them, anyone working with such highly technical software would require a training period.
Image annotation techniques
While computer vision entails a lot of different techniques to study and analyze static images and videos, only four of them are followed in image annotation.
- Bounding box annotation: Bounding box is a geometric square that completely outlines a spotted object and encloses it with boundaries. Each object in the image has it's own bounding box that pools all the key attributes for the algorithm to label the object.
- Polygon annotation: Polygons are used for unstructured objects like cars, buildings, cycles, food items or vegetation. It draws precise polygons around irregularly shaped objects and interprets the uniqueness of object for accurate classification.
- Keypoint annotation: Keypoints or nodal annotation traces the key features of a face to detect the identity of the individual. Keypoint annotation is most used in facial recognition or biometric boarding.
- 3D cuboid annotation: This creates 3D bounding boxes to represent object dimensions like breadth, height and width. It is used mostly during manufacturing of energy efficient, self-drive vehicles or robotics.
Top 5 image recognition software in 2025
These are the top rated image recognition platforms from G2's winter 2024 grid report.
AI image annotation use cases
Our visual world is a significant part of what we do and experience every day, even if we don’t realize it. Machine learning models have widespread applications, with high-quality image annotations the driving force behind many of these, including:
- Autonomous vehicles. Machine learning is a critical part of this field, enabling cars to recognize potential hazards and respond accordingly. An autonomous vehicle's AI system must identify road signs, traffic lights, bike lanes, other vehicles, and even risks such as bad weather.
- Agriculture. Image annotation is a new AI application in farming, but is significantly changing the way agricultural practices operate. Identifying livestock or damaged crops without the need for human intervention upfront can save time, protect vital crop assets, and even reduce human injury.
- Security. Facial recognition is becoming a prevalent part of security systems, which have all been trained using object detection and instance segmentation techniques. Crowd detection, night vision, and traffic motion also use AI tools to keep people safe and prevent crime.
- Urban planning. City planners can turn to image annotation to identify suitable locations for their new infrastructure project. Annotators can train machines to distinguish between green spaces, residential areas, and downtown districts. This technology can also be used for potholes, or road surface defect identification and traffic management.
Look at all those labels!
With image annotation, AI engineers can train machines to effectively detect, identify, and categorize visual materials that businesses use every day. It takes time to set up a quality dataset and label every image, but the well-trained machine you’ll end up with makes the hard work upfront worth the time.
Learn more about object detection in computer vision and pre-train your own neural network for real images and videos.

Holly Landis
Holly Landis is a freelance writer for G2. She also specializes in being a digital marketing consultant, focusing in on-page SEO, copy, and content writing. She works with SMEs and creative businesses that want to be more intentional with their digital strategies and grow organically on channels they own. As a Brit now living in the USA, you'll usually find her drinking copious amounts of tea in her cherished Anne Boleyn mug while watching endless reruns of Parks and Rec.


