



Piense en ver una película o serie de televisión en una plataforma de streaming.
Al usar plataformas de streaming, los usuarios globales transmiten o almacenan localmente archivos multimedia grandes de varios gigabytes (GB) simultáneamente.
El streaming de objetos es lo que ocurre en segundo plano al hacerlo. Cada serie de televisión o película se almacena ya sea como un objeto dividido o un rango montado de objetos. Y la forma en que se almacenan es un ejemplo clásico de almacenamiento de objetos.
¿Qué es el almacenamiento de objetos?
El almacenamiento de objetos, o almacenamiento basado en objetos, es una arquitectura de almacenamiento de datos que almacena datos como objetos o unidades distintas. Estos objetos contienen los datos, metadatos relevantes e identificadores únicos globales (GUID), todos accesibles inmediatamente a través de interfaces RESTFUL, APIs o HTTP/HTTPS. La estructura plana de un sistema de almacenamiento de objetos permite que los datos se almacenen en un único almacén en lugar de archivos en carpetas o bloques en servidores.
El software de almacenamiento de objetos es más adecuado para organizaciones que desean recopilar, almacenar y analizar una gran cantidad de datos. Las soluciones de almacenamiento de objetos son cruciales para habilitar análisis que demandan mucho ancho de banda. Pueden ayudar a las empresas a solucionar un portafolio de almacenamiento fragmentado, recuperar datos más rápido y optimizar recursos.
El almacenamiento de objetos no siempre fue la opción preferida para manejar grandes cantidades de datos. En los primeros días, era más adecuado para gestionar lagos de datos, copias de seguridad y archivos de datos. Luego vino la era del crecimiento explosivo de datos. Una base de datos relacional tradicional era incapaz de manejar la cantidad sin precedentes de datos generados.
Esto obligó a las empresas a replantearse el almacenamiento basado en bloques o archivos, ser resilientes a los datos e ir más allá de la capacidad de almacenamiento. Desarrollado a finales de los años 90 por investigadores de la Universidad Carnegie Mellon y la Universidad de California-Berkeley, el software de almacenamiento de objetos hoy en día puede almacenar y gestionar terabytes (TB) o petabytes (PB) de datos en un único espacio de nombres con la trifecta de escala, velocidad y rentabilidad. Lo que además les obligó a replantearse la infraestructura de TI en las instalaciones es el auge de las aplicaciones nativas de la nube.
Almacenamiento de objetos vs. almacenamiento en bloques vs. almacenamiento de archivos
La cantidad de datos con la que trabajas sigue creciendo cada día, haciendo que la gestión de datos sea aún más abrumadora. Con tres tipos de arquitectura de almacenamiento: almacenamiento de objetos, almacenamiento en bloques y almacenamiento de archivos para elegir, es crucial tener una comprensión sólida de los pros y los contras de cada uno porque la tecnología de almacenamiento que elijas influye significativamente en las decisiones empresariales.
.png)
Almacenamiento de objetos
Las empresas que buscan archivar y respaldar datos no estructurados producidos por dispositivos de Internet de las cosas (IoT) a menudo encuentran que el almacenamiento basado en objetos es la mejor solución. Estos datos no estructurados incluyen contenido web, medios y datos de sensores.
Un sistema de almacenamiento de objetos se basa en un entorno de datos estructuralmente plano en lugar de jerarquías complejas como carpetas o directorios para almacenar datos como objetos. Piense en estos objetos como repositorios o cubos autónomos. Cada uno de ellos almacena datos con identificadores únicos (UID) y metadatos personalizables. Las organizaciones pueden reflejar y ejecutar código de borrado para estos cubos a través de centros de datos y dispositivos de almacenamiento.
Características del almacenamiento de objetos:
- Protocolos de acceso a datos flexibles
- Arquitectura distribuida de escala horizontal
- Gestión de información impulsada por metadatos
- Multi-tenencia dentro de la misma infraestructura
- Espacio de nombres global para mayor transparencia de datos
- Gestión automatizada del sistema para reducir la complejidad
- Protección avanzada de datos mediante codificación de borrado y replicación de datos
Debido a su escalabilidad y fiabilidad, el almacenamiento de objetos se utiliza ampliamente para aplicaciones de almacenamiento en la nube. Además, el esquema de direccionamiento plano facilita la búsqueda y el acceso a objetos individuales.
S3, que originalmente era Amazon S3, es el protocolo de acceso más común que utilizan los almacenes de objetos. Utiliza comandos sin conexión como LIST, GET, PUT y DELETE para acceder a los objetos. Hoy en día, las aplicaciones pueden usar nativamente el protocolo S3 para acceder a archivos, lo que significa que ya no se necesita un sistema de archivos.
Almacenamiento en bloques
El almacenamiento en bloques, o almacenamiento a nivel de bloque, es la forma más antigua y sencilla de almacenamiento de datos. Almacena datos en fragmentos o bloques de tamaño fijo. Cada uno de estos bloques tiene una dirección y almacena unidades de datos separadas en redes de área de almacenamiento (SAN).
En lugar de metadatos personalizables, un sistema de almacenamiento en bloques utiliza direcciones para identificar archivos y una interfaz de sistema de computadora pequeña por internet (iSCSI) para transportarlos desde los bloques requeridos. Este control granular conduce a un rendimiento más rápido cuando tanto la aplicación como el almacenamiento son locales. También habrá más latencia cuando estén más separados.
Las plataformas de almacenamiento en bloques permiten la creación de múltiples rutas de datos y una fácil recuperación al desacoplar los datos de los entornos de usuario y distribuirlos en múltiples entornos. Esto hace que el almacenamiento en bloques sea la opción preferida para los desarrolladores de aplicaciones que buscan soluciones de transferencia de datos rápidas, confiables y eficientes para situaciones de computación de alto rendimiento.
Por ejemplo, una implementación de máquina virtual a nivel empresarial puede aprovechar el almacenamiento en bloques para almacenar el sistema de archivos de la máquina virtual (VMFS). Usar un volumen de almacenamiento basado en bloques para almacenar el VMFS facilita a los usuarios compartir archivos usando el sistema operativo (OS) nativo.
Almacenamiento de archivos
El almacenamiento de archivos, también conocido como almacenamiento a nivel de archivo o almacenamiento basado en archivos, es una metodología jerárquica para almacenar u organizar datos en un dispositivo de almacenamiento conectado a la red (NAS). Funciona de manera muy similar a un sistema de archivos de red tradicional, lo que significa que es fácil de configurar pero viene con solo una ruta al dato.
Por ejemplo, los dispositivos de almacenamiento conectado a la red (NAS) utilizan sistemas de almacenamiento de archivos para compartir datos a través de redes de área local (LAN) o redes de área amplia (WAN). Dado que el almacenamiento de archivos utiliza protocolos comunes a nivel de archivo, los sistemas disímiles generalmente limitan la usabilidad.
Impulsado por un sistema de archivos global, el almacenamiento de archivos utiliza directorios y subdirectorios para almacenar datos. El sistema de archivos es responsable de gestionar diferentes atributos de archivo como la ubicación del directorio, la fecha de acceso, el tipo de archivo, el tamaño del archivo, los detalles de creación y modificación.
El caso de uso perfecto para el almacenamiento de archivos es la gestión de datos estructurados.
Un volumen creciente de datos será un desafío para manejar debido a las crecientes demandas de recursos y problemas estructurales. Algunos de estos problemas pueden resolverse con dispositivos de alta capacidad con abundante espacio de almacenamiento o almacenamiento de archivos basado en la nube.
| Almacenamiento de objetos | Almacenamiento en bloques | Almacenamiento de archivos | |
| Arquitectura | Datos como objetos | Datos en bloques | Datos en archivos |
| Estructura | Plana | Altamente estructurada | Estructurada jerárquicamente |
| Transporte | TCP/IP | FC/iSCSI | TCP/IP |
| Interfaz | HTTP, REST | Directo adjunto/SAN | NFS, SMB |
| Geografía | Puede almacenarse en varias regiones | Puede almacenarse en varias regiones | Disponible localmente |
| Escalabilidad | Infinita | Limitada | Posible solo para almacenamiento de archivos basado en la nube |
| Analítica | Metadatos personalizables para fácil recuperación de archivos | Sin metadatos | Diferentes atributos de archivo para fácil reconocimiento |
| Cuándo usar | Alto rendimiento de transmisión | Base de datos y datos transaccionales | Almacenamiento de datos conectado a la red |
| Mejor caso de uso | Altos volúmenes de datos (estáticos o no estructurados) | Flujos de trabajo intensivos en datos con baja latencia | Copia de seguridad de datos, archivo de datos, intercambio de archivos local y biblioteca centralizada |
La arquitectura distribuida y de escala horizontal del almacenamiento de objetos es posible gracias al acceso paralelo a los datos y a los metadatos distribuidos. Antes de profundizar en la arquitectura, es importante conocer los diferentes componentes del almacenamiento de objetos.
¿Quieres aprender más sobre Soluciones de Almacenamiento de Objetos? Explora los productos de Soluciones de Almacenamiento de Objetos.
¿Cuáles son los componentes del almacenamiento de objetos?
La razón por la que el almacenamiento de objetos es tan atractivo radica en su jerarquía de sistema plano que promueve la accesibilidad, la capacidad de búsqueda, la seguridad y la escalabilidad. Este entorno plano está compuesto por múltiples componentes que facilitan el almacenamiento de grandes volúmenes de datos a través de redes distribuidas. Estos componentes son:
Objeto
Un objeto es la unidad fundamental de un sistema de almacenamiento basado en objetos. Contiene datos con atributos como metadatos relevantes e identificadores únicos.
Hay tres tipos de objetos:
- Objeto raíz: Identifica el dispositivo de almacenamiento y sus atributos
- Objeto de grupo: Ofrece un directorio al subconjunto lógico de objetos en un dispositivo de almacenamiento de objetos
- Objeto de usuario: Mueve datos de aplicación para propósitos de almacenamiento y almacena atributos relacionados con el usuario y el almacenamiento
Dispositivo de almacenamiento basado en objetos (OSD)
Un dispositivo de almacenamiento basado en objetos es responsable de gestionar el almacén de objetos local, servir y almacenar datos desde la red. Es la base de la arquitectura de almacenamiento de objetos y consta de un disco, memoria de acceso aleatorio (RAM), un procesador y una interfaz de red.
Cuatro funciones principales de un dispositivo de almacenamiento basado en objetos son:
- Almacenamiento de datos: Almacena y recupera datos de manera confiable a través de IDs de objetos
- Disposición inteligente: Optimiza la disposición de datos y la pre-carga usando el procesador
- Gestión de metadatos: Gestiona metadatos para los objetos almacenados
- Seguridad: Inspecciona las transmisiones entrantes para seguridad
Los dispositivos de almacenamiento basados en objetos funcionan de manera similar a las redes de área de almacenamiento (SAN) en sistemas de almacenamiento tradicionales, pero pueden ser dirigidos directamente en paralelo sin la intervención de una matriz redundante de discos independientes (RAID).
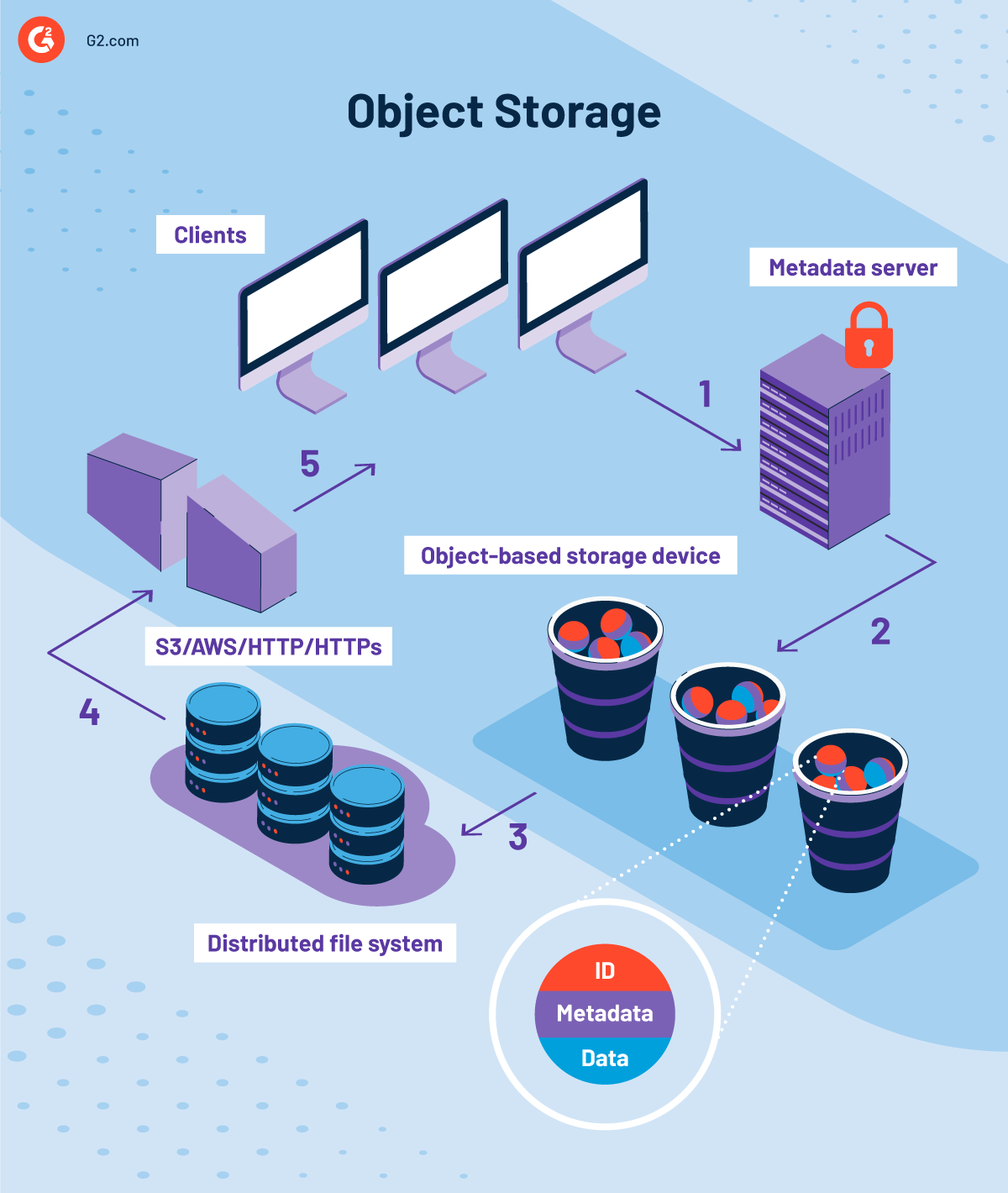
Sistema de archivos distribuido
Un sistema de archivos distribuido aprovecha un sistema de archivos instalable para permitir que los nodos de computadora lean y escriban objetos en el dispositivo de almacenamiento de objetos. Sus funciones clave son:
- Interfaz de sistema operativo portátil (POSIX): Facilita operaciones estándar del sistema como Abrir, Leer, Escribir y Cerrar para el sistema de almacenamiento subyacente
- Caché: Proporciona caché para los datos entrantes en el nodo de cómputo
- Striping: Gestiona el striping de objetos a través de múltiples dispositivos de almacenamiento de objetos
- Montaje: Utiliza control de acceso para montar sistemas de archivos en la raíz
- Controlador de interfaz de sistema de computadora pequeña por internet (iSCSI): Implementa el controlador iSCSI para facilitar extensiones de objetos y carga de datos
Servidor de metadatos
Un servidor de metadatos (MDS) actúa como un repositorio central y facilita el almacenamiento, gestión y entrega de metadatos utilizando un metamodelo de almacén común (CWM) y una arquitectura de metadatos abierta.
Coordina con nodos autorizados para asegurar la interacción adecuada entre nodos y objetos. También mantiene la consistencia de caché para los mismos archivos. La eliminación de servidores de metadatos resulta en un alto rendimiento y escalabilidad lineal en entornos de red de área de almacenamiento (SAN).
Las funciones clave del servidor de metadatos son:
- Autenticación: Identifica y autentica dispositivos de almacenamiento basados en objetos que esperan unirse al sistema de almacenamiento
- Gestión de acceso: Gestiona el acceso a archivos y directorios para solicitudes de operación de nodos
- Coherencia de caché: Actualiza cachés locales antes de permitir que múltiples nodos usen el mismo archivo
- Gestión de capacidad: Asegura el uso óptimo de los recursos de disco disponibles
- Escalado: Gestiona la gestión de metadatos a nivel de archivo y directorio para la escalabilidad
Fábrica de red
La fábrica de red es responsable de conectar toda la red, es decir, dispositivos de almacenamiento basados en objetos, nodos de cómputo y servidores de metadatos en una sola fábrica. Otros componentes clave de la red son:
- Protocolo de interfaz de sistema de computadora pequeña por internet (iSCSI): Un protocolo de transporte básico para datos y comandos a los dispositivos de almacenamiento de objetos (OSDs)
- Soporte de comando de llamada a procedimiento remoto (RPC): Facilita la comunicación entre servidores de metadatos y nodos de cómputo
¿Cómo funciona el almacenamiento de objetos?
Los volúmenes de almacenamiento de objetos funcionan como repositorios autónomos y almacenan datos en unidades modulares. Tanto el identificador como los metadatos detallados juegan un papel clave en el rendimiento superior de la distribución de carga. Una vez que creas un objeto, puede copiarse fácilmente a nodos adicionales, dependiendo de las políticas existentes. Los nodos con alta disponibilidad y redundancia pueden estar dispersos geográficamente o almacenados en el mismo centro de datos.
Los entornos de computación en la nube pública permiten que el almacenamiento de objetos sea accedido a través de HTTP o API REST. La mayoría de los proveedores de servicios de almacenamiento en la nube pública suelen ofrecer APIs que ellos mismos construyen. Algunos de los comandos comunes enviados a HTTP incluyen PUT (para crear objetos), GET (para leer objetos), DELETE (para purgar objetos) y LIST (para listar objetos).
¿Cómo mueve datos un sistema de almacenamiento de objetos?
Operaciones de LECTURA:
- Un cliente se conecta con el servidor de metadatos
- El servidor de metadatos valida la identidad del nodo
- El servidor de metadatos devuelve una lista de objetos en dispositivos de almacenamiento de objetos
- El servidor de metadatos valida la identidad del nodo
- Se envía un token de seguridad al nodo para acceder a objetos específicos
- El nodo empaqueta los datos
- El dispositivo de almacenamiento de objetos transfiere los datos al cliente
Operaciones de ESCRITURA:
- Un cliente solicita al servidor de metadatos escribir un objeto
- El servidor de metadatos autoriza al nodo con un token de seguridad
- El nodo empaqueta la solicitud de ESCRITURA y la envía a dos OSDs al mismo tiempo
- El nodo procesará la solicitud e informará al cliente
¿Cuáles son los beneficios del almacenamiento de objetos?
Lograr un rendimiento máximo en hardware de servidor de productos básicos se vuelve mucho más fácil con un sistema de almacenamiento de objetos. Si tu empresa tiene un lago de datos en crecimiento exponencial, es decir, un conjunto de datos no estructurados, el almacenamiento de objetos es imprescindible para organizar, gestionar y acceder a los datos. Aquí está el porqué:
- Facilidad de búsqueda: Los objetos en un sistema de almacenamiento de objetos generalmente se almacenan con IDs únicos, metadatos personalizables y URLs HTTP. Todo esto hace que sea muy fácil para los usuarios encontrar objetos y realizar operaciones de LECTURA/ESCRITURA. Esta facilidad de acceso y búsqueda hace que los sistemas de almacenamiento de objetos sean una opción preferida para las organizaciones que manejan datos no estructurados.
- Escalabilidad ilimitada: Quizás el mayor beneficio de los sistemas de almacenamiento de objetos es que pueden escalar fácilmente cuando los datos crecen. La arquitectura estructural plana permite la adición horizontal de nodos y facilita la gestión de grandes volúmenes de datos.
- Agilidad: Los sistemas de archivos tradicionales y las bases de datos no suelen ser ágiles y requieren un mantenimiento profesional riguroso. Los sistemas de almacenamiento de objetos pueden gestionarse a sí mismos basándose en instrucciones de metadatos y permiten a los desarrolladores cambiar aplicaciones sin depender del equipo de infraestructura. Esta agilidad es lo que hace que la gestión del ciclo de información sea eficiente para las organizaciones que adoptan soluciones de almacenamiento de objetos.
- Recuperación rentable: Un sistema de almacenamiento de objetos puede copiar objetos a más de un nodo al crear un objeto. En el caso poco probable de desastres, el tiempo de recuperación de datos se vuelve más fácil para las organizaciones ya que estos nodos están ubicados en todo el mundo. Esto elimina la necesidad de almacenar grandes volúmenes de datos en hardware físico y hace que el almacenamiento de objetos sea rentable.
- Seguridad mejorada: Las soluciones de almacenamiento de objetos basadas en la nube permiten a las empresas almacenar datos de manera segura con cifrado en tránsito y en reposo. Muchos proveedores de almacenamiento en la nube también ofrecen otras características de seguridad como protección contra ransomware, multi-tenencia segura, autenticación de protocolo ligero de acceso a directorios (LDAP), protección contra derrames de datos, y más.
Cuándo usar almacenamiento de objetos:
- Recuperación ante desastres
- Aplicaciones móviles y basadas en internet
- Copia de seguridad y recuperación de datos críticos
- Extensión de almacenamiento en las instalaciones con almacenamiento en la nube híbrida
- Almacenamiento de escritura única y lectura múltiple (WORM) para archivos de cumplimiento
- Para almacenar fuentes de datos no estructurados, como archivos multimedia
Dicho esto, los sistemas de almacenamiento de objetos no son adecuados para la gestión de datos transaccionales y de bases de datos. Además, no permiten la alteración de una sola pieza de datos. Para editar una parte de un bloque, uno tiene que leer y escribir completamente todo el objeto.
¿Cómo pueden los sistemas de almacenamiento de objetos proteger los datos del ransomware?
Con sistemas complejos vienen vulnerabilidades complejas. Por eso es muy importante tener una estrategia de recuperación sólida. Una de las mejores maneras de manejar el ransomware es evitar la infección restaurando datos a través de una copia de seguridad segura. Y el almacenamiento de objetos ofrece la solución perfecta para esto. ¿Por qué?:
- No hay cambios de datos no autorizados: El almacenamiento de objetos tiene una arquitectura de almacenamiento de datos inmutable, lo que significa que no puede cambiarse una vez escrito. Eso es porque los datos se escriben usando la tecnología de escritura única y lectura múltiple (WORM). Además, los administradores tienen la libertad de habilitar la inmutabilidad a nivel de cubo. Dado que los datos no pueden modificarse, no pueden ser cifrados por ransomware. Algunos proveedores de almacenamiento en la nube también ofrecen funcionalidad de bloqueo de objetos que funciona de la mano con WORM para proteger los datos a nivel de dispositivo.
- Múltiples copias de datos: Cada vez más ciberdelincuentes continúan usando variantes de ransomware para atacar copias de seguridad de datos en lugar de los datos. La función de versionado de datos de un sistema de almacenamiento de objetos te permite crear una nueva copia de datos mientras los alteras. Esto significa que siempre habrá una copia de los datos originales incluso si un archivo es cifrado por ransomware.
Mejores prácticas de almacenamiento de objetos
Sacar el máximo provecho del almacenamiento de objetos no es fácil. Independientemente del tipo de datos no estructurados con los que tu organización trate, es importante seguir las mejores prácticas para gestionar tus datos.
- Descubre cargas de trabajo intensivas en datos: El primer paso para implementar almacenamiento de objetos es identificar cargas de trabajo y aplicaciones intensivas en datos. Busca aplicaciones que requieran rendimiento de transmisión, no altas tasas de transacción. Si bien el almacenamiento de objetos es ideal para conjuntos de datos más grandes, piensa si tiene sentido para tus necesidades de aplicación y almacenamiento de datos.
- Analiza la prueba de concepto: Realizar una prueba de concepto es esencial para identificar la plataforma de almacenamiento de objetos adecuada. Esto te ayuda a evaluar las capacidades del proveedor y ver si cumplen con tus necesidades. Considera usar máquinas virtuales para pruebas no disruptivas para asegurar el éxito del proyecto.
- Prepárate para fallos de dispositivos: Varios proveedores de almacenamiento en la nube ofrecen 1 petabyte (PB) en un solo dispositivo. Estos dispositivos te protegen de la pérdida de datos y vienen con precios rentables, pero generalmente toman más tiempo de reconstrucción después de un incidente de fallo de dispositivo. Por eso es mejor dividir grandes servidores en nodos independientes. También puedes considerar configuraciones de clúster habilitadas para codificación de borrado que hacen que los dispositivos sean resistentes a fallos.
- Satisface las necesidades de los usuarios: Con los sistemas de almacenamiento de objetos, puedes consolidar usuarios y aplicaciones en un entorno compartido en un solo sistema. Los usuarios necesitan diferentes niveles de servicio junto con capacidad de almacenamiento y seguridad. Aprovechar la calidad del servicio (QoS) y la multi-tenencia te ayudará a satisfacer estas necesidades.
- Aprovecha el poder de los metadatos enriquecidos: Los metadatos facilitan el proceso de análisis de datos y extracción de información de una base de datos de almacenamiento de objetos. Por eso es crucial aprovechar las etiquetas de metadatos integradas para hacer que los grupos de almacenamiento y los conjuntos de datos sean buscables.
- Automatiza el flujo de trabajo con integraciones: Las soluciones de objetos generalmente dependen de la API S3 para regular cómo las aplicaciones controlan los datos. Ahora, la API S3 viene con más de 400 verbos que pueden manejar sin problemas diferentes funciones relacionadas con informes, gestión e integraciones. Las organizaciones deben aprovechar esta característica del almacenamiento de objetos y trabajar con DevOps para automatizar flujos de trabajo.
Casos de uso de software de almacenamiento de objetos en la nube
Lo que hace que las opciones de almacenamiento de objetos sean la primera opción para el almacenamiento empresarial es su capacidad para almacenar grandes cantidades de datos no estructurados en un grupo plano. Aquí están las industrias que continúan aprovechando el almacenamiento de objetos a través de servicios en la nube:
- Medios y entretenimiento: Debido a su escalabilidad, las industrias de medios utilizan el almacenamiento de objetos para almacenar y gestionar grandes cantidades de archivos multimedia y activos multimedia. La presencia de metadatos facilita a las organizaciones identificar y acceder a estos archivos en el momento de urgencia.
- Big data: Conteniendo conjuntos de datos diversos y grandes, el big data apenas cabe en bases de datos. Por eso las organizaciones que aprovechan el análisis de big data prefieren usar almacenamiento de objetos. La naturaleza escalable del almacenamiento de objetos les permite almacenar petabytes de datos de redes neuronales y aprendizaje automático para entrenar modelos.
- Salud: Las organizaciones de salud necesitan almacenar grandes cantidades de datos, mantenerlos seguros y cumplir con regulaciones de protección de datos como el Reglamento General de Protección de Datos (GDPR) y la Ley de Privacidad del Consumidor de California (CCPA). También necesitan almacenar datos que pueden no ser accedidos con frecuencia y proporcionar una vista uniforme de los datos del paciente a los médicos. El almacenamiento de objetos basado en la nube y económico cumple fácilmente con todos estos requisitos.
- Almacenamiento intensivo de datos: Las organizaciones que manejan servicios de archivos o bases de datos de clientes también se benefician del almacenamiento de objetos. La naturaleza de su negocio requiere que optimicen el almacenamiento de datos de manera fácilmente accesible. El almacenamiento de objetos es la solución ideal que cumple con todos estos requisitos.
- Almacenamiento como servicio: El almacenamiento de objetos también es la solución de almacenamiento preferida para empresas que buscan almacenamiento compatible con AWS S3 o S3. La mayoría de estas empresas no quieren implementar sistemas de almacenamiento locales o buscan funciones avanzadas como multi-tenencia, controles de calidad de servicio, y más. Y eso hace el caso para la adopción del protocolo o API S3.
- Copia de seguridad y recuperación: Algunas organizaciones también usan almacenamiento de objetos para propósitos de copia de seguridad y recuperación de datos. Lo hacen para evitar la pérdida de datos al respaldarlos en nodos en diferentes centros de datos. Tales organizaciones deben buscar la funcionalidad WORM al elegir un proveedor de almacenamiento de datos en la nube.
- Almacenamiento en frío: Dependiendo de la naturaleza de su negocio, las organizaciones también pueden necesitar almacenar datos inactivos que no se acceden con frecuencia. Esta colección de datos se conoce como almacenamiento en frío. Las soluciones de almacenamiento de objetos son rentables cuando se trata de almacenar este tipo de datos.
- Almacenamiento de artefactos: Los artefactos son colecciones de registros y archivos de versión generados durante el ciclo de vida de una aplicación. Las organizaciones a menudo prefieren almacenar estos artefactos para pruebas posteriores. El método único de distribución de URL del almacenamiento de objetos facilita a los desarrolladores almacenar y acceder a este tipo de archivo.
Software de almacenamiento de objetos
Elegir el software de almacenamiento de objetos adecuado es crucial para almacenar datos no estructurados escalables. Si estás buscando características robustas que permitan flexibilidad, rendimiento y mayor capacidad, deja que el software de almacenamiento basado en objetos haga el trabajo pesado.
Para ser incluido en esta categoría, el producto de software debe:
- Almacenar datos no estructurados y metadatos relevantes
- Facilitar la recuperación de datos a través de APIs o HTTP/HTTPS
- Ser ofrecido por proveedores de servicios en la nube
*A continuación se presentan las 5 principales soluciones de software de almacenamiento de objetos líderes del Informe Grid® de Otoño 2021 de G2. Algunas reseñas pueden estar editadas para mayor claridad.
1. Amazon Simple Storage Service (S3)
Amazon Simple Storage Service (S3) viene con una interfaz de servicios web simple que te permite almacenar y recuperar datos desde cualquier lugar en la web. Es conocido por su escalabilidad, fiabilidad e infraestructura económica.
Lo que les gusta a los usuarios:
“Podemos almacenar nuestros datos y acceder a ellos en cualquier momento. Podemos crear muchos usuarios IAM y proporcionarles acceso. Podemos acceder al sitio por móvil. Podemos crear un sitio de entorno de prueba y compartir la URL con el cliente. El equipo de soporte de S3 es muy técnico. Te ayudan y asisten si los necesitas. Su seguridad es excelente. Los datos de nuestro cliente siempre están seguros y podemos descargarlos en cualquier momento.”
- Reseña de Amazon S3, Atul S.
Lo que no les gusta a los usuarios:
“Es un poco complejo cuando configuramos AWS S3 por primera vez, ya que tenemos que crear un cubo a través de la consola, configurar políticas, elegir entre varias configuraciones, un poco de dolor de cabeza para los principiantes. El principal problema que personalmente siento con AWS es que al jugar con las configuraciones de AWS S3 sin conocimientos avanzados, se termina filtrando los archivos en internet o no sirviendo en absoluto.”
- Reseña de Amazon S3, Heena M.
2. Google Cloud Storage
Google Cloud Storage ofrece almacenamiento de objetos confiable y seguro con características como múltiples opciones de redundancia, fácil transferencia de datos, clases de almacenamiento y más. También permite la configuración de datos usando la gestión del ciclo de vida de objetos (OLM).
Lo que les gusta a los usuarios:
“Google Cloud Storage es una plataforma de almacenamiento increíble que tiene un rendimiento de clase alta, fiabilidad y gran asequibilidad para todas mis necesidades de almacenamiento. En mi posición de trabajo donde tengo que manejar muchos datos, es muy fácil mover datos al proceso de análisis con la ayuda de Google Cloud Storage usando BigQuery y API para la extracción de datos.”
- Reseña de Google Cloud Storage, Kelly T.
Lo que no les gusta a los usuarios:
“Los datos pueden terminar en manos de terceros. La seguridad es responsabilidad de la empresa, algo que puede traer problemas al usuario si hay fallos. No está disponible el control total de acceso a los datos. Se requiere acceso a internet en todo momento.”
- Reseña de Google Cloud Storage, Corbet T.
3. Azure Blob Storage
Azure Blob Storage es una solución de almacenamiento de objetos escalable ideal para computación de alto rendimiento, aplicaciones nativas de la nube y aprendizaje automático. Permite que los datos sean accedidos desde cualquier lugar a través de HTTP/HTTPS.
Lo que les gusta a los usuarios:
“Blob storage es la solución de almacenamiento principal en Microsoft Azure. Tiene muchas integraciones y casos de uso. Las principales características fuertes son capacidad infinita, diferentes tipos de redundancia dependiendo de tus necesidades y presupuesto, y puntos finales de red virtual.
La política de acceso flexible basada en tokens SAS te permite dar acceso permanente y temporal sin necesidad de revocarlo manualmente. Muchas herramientas que pueden acceder a cuentas de almacenamiento, incluso puedes abrirlo en SQL Server Management Studio y gestionar tus datos a través de él. Velocidad increíble, los BLOBs son mucho más rápidos incluso que los discos SSD locales de las VMs de Azure.”
- Reseña de Azure Blob Storage, Gleb M.
Lo que no les gusta a los usuarios:
“La administración es un poco complicada. Ahora hay un RBAC, pero anteriormente solo eran los tokens SAS. No hay una manera simple de usar un dominio personalizado con certificados SSL, hay que usar CDN.”
- Reseña de Azure Blob Storage, Aleksander K.
4. DigitalOcean Spaces
DigitalOcean Spaces es una solución de almacenamiento de objetos compatible con S3 que viene con una red de entrega de contenido (CDN) integrada y una interfaz de usuario (UI) de arrastrar y soltar o API para crear un espacio de almacenamiento confiable.
Lo que les gusta a los usuarios:
“DigitalOcean Spaces es una gran herramienta para almacenar imágenes y archivos para tus aplicaciones. Es fácil de integrar con aplicaciones basadas en Java usando el SDK de Amazon. Es muy amigable de usar y acceder usando la UI de DigitalOcean. También es asequible para un solo desarrollador. Lo uso para mi aplicación todos los días.”
- Reseña de DigitalOcean Spaces, Sonam S.
Lo que no les gusta a los usuarios:
“Algo que no me gusta de los espacios es la interfaz de usuario. Además, puedes enfrentar interrupciones a veces con el espacio. Puede que necesites revisar la página de estado de DigitalOcean ocasionalmente.”
- Reseña de DigitalOcean Spaces, Sachin A.
5. IBM Cloud Object Storage
IBM Cloud Object Storage ofrece almacenamiento en la nube escalable y rentable para datos no estructurados. Viene cargado con características como transferencia de archivos de alta velocidad, servicios integrados, ofertas de múltiples regiones y más.
Lo que les gusta a los usuarios:
“Me gusta la opción de clase de almacenamiento en la nube de IBM. IBM proporciona cuatro tipos de opciones de almacenamiento como Activo (Estándar), Smart Tier, Cool (Vault), Cold Vault. En nuestra empresa, cada miembro del equipo de TI tiene una cuenta en la nube de IBM y usa diferentes servicios según su trabajo. Como miembro del equipo de ciberseguridad, monitoreo el sistema y almaceno datos de registro en el nivel activo de IBM.
Más importante aún, la empresa tiene copias de seguridad en el servicio Cold Vault de IBM. Lo probé y puedo decir que es seguro y robusto para nuestra empresa. El proceso de migración fue fácil y rápido gracias al servicio de soporte de IBM. Hicieron un muy buen trabajo. Durante mis pruebas de seguridad, el servicio de IBM fue el mejor entre los servicios en la nube. El rendimiento de la verificación de cumplimiento fue el mejor.”
- Reseña de IBM Cloud Object Storage, Nikola M.
Lo que no les gusta a los usuarios:
“Encontré un par de veces que el sistema se retrasaba y me hacía volver a cargar los datos para almacenarlos.”
- Reseña de IBM Cloud Object Storage, Matthew B.
Almacena datos de manera sostenible con capacidades de múltiples petabytes
Las necesidades de almacenamiento de datos modernas deben lograr permanencia, disponibilidad, escalabilidad y seguridad (PASS) para almacenar y gestionar grandes volúmenes de datos no estructurados. Las soluciones de almacenamiento de objetos en la nube no solo cumplen con todos estos requisitos, sino que también vienen sin la carga de costos. Por eso las organizaciones están aprovechando cada vez más el software de almacenamiento de objetos para crear nubes públicas, privadas o empresariales.
Aprende más sobre cómo elegir el proveedor de almacenamiento en la nube adecuado para escalar el almacenamiento de datos no estructurados mientras se mantiene la eficiencia de costos.

Sudipto Paul
Sudipto Paul is a former SEO Content Manager at G2 in India. These days, he helps B2B SaaS companies grow their organic visibility and referral traffic from LLMs with data-driven SEO content strategies. He also runs Content Strategy Insider, a newsletter where he regularly breaks down his insights on content and search. Want to connect? Say hi to him on LinkedIn.

