



Raising the level of behavioral intelligence in computers.
When we’re at our best, we don’t get confused about making everyday life decisions.
We know exactly when to wake up, brew a cup of coffee, and leave for work. Our subconscious is strong enough to get us through our day without conflict of interest.
What humans have acquired with evolution is being replicated in computers through an activation function. Mostly used in deep neural networks, the activation function creates a “smart'' response to external user stimuli, just like the human nervous system.
In the business sphere, the activation function is a part of artificial neural network software that can be integrated into your business applications. It validates your business models and takes a rain check on data-centric matters. The more accurate your business model is, the deeper you penetrate your target sales market.
The activation function is a core feature of deep learning introduced between the mid-2000s to 2010 (with theoretical proposals dating back to 1990). Deep learning is an artificial intelligence (AI) technique that works on large datasets and high graphical computational power (GPU) or central processing unit (CPU) power.
Because of this, it learns data patterns quickly, delivers accurate outcomes, and solves problems on a large scale.
What is an activation function?
The activation function, also known as the transfer function, is used to determine the output of an artificial neural network (ANN), which is a supervised deep learning method. The activation function decides the category of the input by activating the correct decision node. The node determines an output value and submits it to the neural network.
Once ANN is fed and validated with training data, it is run on test data. The test data evaluates the accuracy of the neural network to create a good fit model.
Neural networks are used for category classification. Categories, in general, are quantitative variables into which data is grouped. Examples could be an old person or young person, a tall person or a short person, an employed person or an unemployed person. This categorical analysis of data using artificial neural networks is known as data classification.
What is an artificial neural network?
If you have read about artificial neural networks, you might know their tiered structure. A neural network consists of a minimum of three layers: the input layer, the hidden layer, and the output layer. However, it can go up to 7 layers. There has yet to be a consensus on how many layers a deep neural network can have.

The input layers accept data from the user, along with weights and added bias. The hidden layers process information. Finally, the activation layer calculates output.
Weights and biases are externally added to the overall net input value. You often run neural networks iteratively, with the weights updated at each new row of data. While processing data, weights go up and down quite often whenever the actual class matches the predicted class. The process gets iterated multiple times until you obtain a certain degree of accuracy.
An artificial neural network fires its decision-making nodes like the human brain fires electrical impulses.
For any kind of neural network, the range of an activation function fluctuates between -infinity to +infinity. The weight parameters are often randomly declared as 0.01, 0.05, 0.1, and so on.
Under all circumstances, the activation function remains nonlinear and applicable to any data input.
¿Quieres aprender más sobre Software de Redes Neuronales Artificiales? Explora los productos de Red neuronal artificial.
Why is activation function important?
The activation function aims to raise a machine's consciousness and make it aware of external objects. In terms of structure, it mimics the human brain’s central nervous system.
Activation functions in neural networks that are integrated into enterprise resource planning (ERP) systems label your company data. Every stakeholder can use AI automation to review their reports, handle projects, or study consumer data points.
It also detects real-life objects through sonics for a blind person to walk freely. It can be used in metal scanners to detect unwanted objects at the airport. Some industries use this technology in surveillance and security systems for facial recognition. Smart vacuums, pods, and glass cleaners based on object detection have also been launched worldwide.
The nonlinear activation function is the most important element of a neural network. It runs the chores, triggers decisions, and classifies data.
The formula for the activation function
The activation function processes the data in a way that doesn't produce any erroneous output. It accurately defines the category of the data. It carries out all the operations, from accepting input to performing the hypothesis to predicting the correct category.
Input at different stages is collated using the following mathematical formula for the activation function:
The formula for activation function:
y + residue = ∑ (weights*input + bias).
Along with y, you also get an error. Whenever an algorithm works on input data, it gives out a small error value along with the desired output. That error value is known as the residue value. This value can be fed into the next cycle of data entry, a process known as backpropagation.
What is backpropagation?
Backpropagation reduces the error residue of a neural network. It re-transmits the output to the input layer to stabilize numbers. The quick and simple process iterates backward to avoid back-and-forth between the layers.
The algorithmic flow chart of backpropagation travels involuntarily like this:
- The output moves back to the input layer of the neuron.
- The value is added to the new input, along with their weights.
- The output of each layer, from input to hidden to output, is calculated.
- The weights are again adjusted to reduce error scope.
- The process is repeated until the user receives desired output.
The formula for backpropagation is
Backpropagation error = actual output - desired output.
Did you know? Backpropagation models are used to train feedforward neural networks to avoid decision loops. This type of artificial neural network moves forward and not backward. During data flow, input nodes receive data that travels through hidden layers and exits through the output layer.
What are gradients?
In the activation function, gradients are the slope of the function curve. Input derivatives evaluate them at a given point in space. The higher the gradient, the steeper the slope and the faster a model will learn. It simply represents the change of output on a graph.
What is batch size?
The batch size is set between 0 and n. It defines the number of training data samples an ANN model sees before updating the weights. So during every update, the batch size is 1. But if you set the batch size to 50, the network won’t be activated until the model runs on 50 training samples. Batch size is a cost-efficient technique, as updating weights manually gets very expensive.
Linear activation function vs. non-linear activation function
An activation function can be linear or non-linear.
-png.png)
A linear function is plotted on a straight line and has an infinite output range. It’s used to make simple data-related observations. A linear model is monotonic (either increasing, decreasing, or flat), a supervised form of machine learning that can train specific datasets.
Linear activation functions are used within normal data distribution and are quantitative. Nominal or ordinal variables are converted into dummy variables to run the linear algorithm. Although a linear activation function can be used for labeling data, it’s not ideal. The monotony of a linear activation function makes it unsuitable for accurate prediction.
In contrast, a non-linear function has a specific range of values for the desired output. It tests the scope of a problem much faster than a linear function. A nonlinear function is used to classify complicated data types, including patterns, speech, video, or audio.
8 types of activation functions in artificial neural network
The current popular convolutional neural networks like R-CNN, Mask R-CNN, or you only look once (YOLO) use nonlinear activation functions to categorize objects. Let's learn about the types of nonlinear functions in detail.
1. Logistic function
The logistic or sigmoid function is a special function that looks like an S-shaped graph and ranges between 0 and 1. It’s used for binary classifications with only two possible outcomes for the predicted variable.

For example, if you want to classify an airplane in an image, the sigmoid activation function will deliver the output as “yes”. It suggests that a given image contains an airplane.
The sigmoid activation function is calculated with this formula:
f(z) = 1.0 / (1.0 + e-z),
Where e is a mathematical constant that increases or decreases based on input data size. Because of a constrained graphical area, output falls in a loop. ReLU function overcomes this.
Tip: While using an activation function, use “Xavier normal” or “Xavier uniform” weight initialization to declare inputs. This technique scales your answers between “yes” and “no.”
2. Hyperbolic tangent function (TanH)
TanH is similar to sigmoid, but it’s a bit better in terms of output accuracy. It ranges between -1 to +1 and also includes negative values.

In the TanH function, the larger the input value (more positive), the closer the output is to 1. Similarly, the smaller the input value, the closer the output is to -1.
The TanH activation function can be derived from this formula:
TanH (x) = (e^x – e^-x) / (e^x + e^-x).
In the above-mentioned formula, e stands for exponential constant. As TanH is a nonlinear function, it has area gradients that can be easily computed within the range of (0,1) and (1,1). The diverse nature of the TanH function makes it more accurate for business procedures.
You can create a TanH function using the code below. It’s written and compiled in integrated data environments like Jupyter or Spyder.

Source: machinelearningmastery.com
3. ReLU function
The rectified linear (ReLU) activation function is a nonlinear or piecewise linear function that returns either the same value or 0.

You can find it with the following formula:
f(x) = max (x); if x>0,
f(x) = 0; if x<0
If the input value is positive, the output of the activation function is the same as the input. But if the value is negative, the output is zero. The ReLU function has one of the highest accuracies and is used in all the latest classifiers like CNN, R-CNN, multilayer perceptrons, self-organizing maps, and generative adversarial networks.
At an initial glance, ReLU seems linear because it’s a steeply increasing function and equalizes y to x. However, it’s a nonlinear function that especially returns 0 for negative input.
For inputs less than 0, ReLU deactivates the decision-making neurons and produces “0” as an output. If the output comes out to be 0, that means the data class has not been defined. This is also known as the “dying ReLU problem”. To return a positive value, the ReLU function needs to be backed up with something. Otherwise, the processing comes to a halt.
Here is a relevant code snippet for defining the ReLU activation function.
#to define ReLU
def ReLU(x):
if x>0:
return x
else:
return 0
#to enter and store a set of input values and plot them
from matplotlib import pyplot
from matplotlib import NumPy
def relu(z):
return max(0.0, z)
input = [z for z in range(-1, 10)]
# run ReLU on every input value
output = [relu (z) for z in input]
# plot our graph
pyplot.plot(series_in, series_out)
pyplot.show()
ReLU has better output accuracy and lesser error value than TanH and sigmoid. The specificity of the ReLU function depends on the kind of pre-trained weights being added along with the input data.
Tip: Specificity is the true negative rate that describes the presence or absence of an output category. It’s calculated using the formula:
Specificity = True Negative /(True Negative + False Positive)
Here:
Negative: the absence of a category
Positive: the presence of a category
4. Leaky ReLU function
The leaky ReLU function is an activation function that aims to solve the inconsistencies of the ReLU function and process faster. It’s an approved version of the ReLU function and is nonlinear and differentiable in nature.

Instead of defining the function as 0 for negative values of x, Leaky ReLU simply multiplies x by 0.01. So, whenever f(x) < 0, the graph remains moving upwards without degenerating. Therefore, the graph of the original ReLU function changes a bit to accommodate the additional value of x.
f(x) = max (0.01*x, x) /*for all values of x*/
This function returns x, for positive data values, and a decimal value of x, for a negative value.
In this way, the neurons stay activated even when the input is negative.
5. Softmax activation function
The softmax layer is the last layer of a deep neural network. It returns the class and location of the input, as well as the value of location coordinates and axial parameters.
The softmax layer converts a set of input values into a singular output vector (say v), which is fed into a support vector machine (SVM). The results are twofold: the class of the object and its location. One of the best examples of this is object recognition.
The term softmax depicts the “smooth functioning” of an activation function. This layer has been recently added to modern neural networks to process data in less time.
6. Linear function
Linear activation, also known as no activation, is a linear model that displays a direct proportion between input and output. The data you feed to the input node and the resultant matrix are the same in nature.

As linear function is a strictly increasing or decreasing function, it has two major drawbacks:
- Due to the absence of error, you cannot use backpropagation in this type of neural network.
- A linear activation function will clump a neural network's layers into one single layer.
Mathematically, it is denoted by:
f(x) = x.
The one-dimensional nature of a linear activation function doesn’t make it suitable for classifying large volumes of data.
7. Exponential linear units (ELUs)
The exponential linear unit differs from other linear activation functions. This algorithm processes negative data elements into useful data categories. If the input value decreases, the output is capped at -1, as the exp (x) limit goes to -infinity. ELU activation function calculates the real value of the input regardless of how low it can be. The range can go up from -infinity to +infinity.
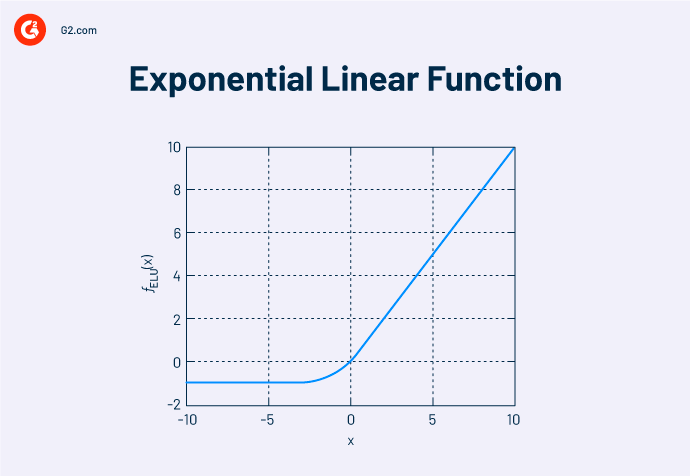
If the input values are really small, there will be no information transmission from one node to the other node of the neural network. The output will be the same as the input.
The difference between ELU and other functions is that ELU gives negative outputs. A negative output means the neural network acquires natural gradients. The features extracted from natural gradients make the output more accurate.
Tip: A derivative is a slope of a tangent line. If the derivative is positive, it means the function is increasing. When it’s negative, it means the function is decreasing. The function may have achieved a maximum or minimum if it's zero.
8. Binary step function
The binary step function is a nonlinear activation function that sets a threshold for the input values. If the input values surpass that threshold, the neurons activate and return the value 1. If not, it returns the value as 0.
This activation function mainly creates a binary classifier (yes/no). However, it might not be helpful if your database has multiple categories, classes, or column headers.

For example, suppose you have a supplier database consisting of transportation, warehouse, raw material, and assembly costs. You want to calculate a competitive supplier cost. You must co-relate between your input and predicted variables for each expected cost.
In that case, the binary step function isn’t suitable.
This is a simple activation function that can be declared with a simple if-else condition in python:
def bin(x): /function declaration and body
if x<0:
return 0
else:
return 1
bin(5), bin(-1) /function call
Output: (1,0)
Pros and cons of activation function
Different activation functions are used to solve different data classification problems. Some might be used for categorizing nominal data, while others would be more categorical in nature. The activation function is a way for your neural network to describe data in the best way possible, which takes the burden off your analytics teams.
Not every activation function is cross-functional in nature. Its actual use case is labeling your business data in a way that makes sense. They have a defined range of outputs and added errors, which can change your predicted outcomes. The neural network results in the same net input without an activation function. Discrepant data metrics won’t lead your analytics team anywhere.
To decide which activation function is apt for your data, check out the pros and cons:
-
Linear activation function gives you a range of similar outcomes, not necessarily in a binary (yes/no) fashion. It fires the right decision node and categorizes data faster than another algorithm. Because of its simplicity, it is one of the most preferred functions for image classification and binary classification.
However, a linear function is a constant slant, increasing or decreasing. That’s why we can’t reverse-check our inputs or the weights.
- Logistics sigmoid is a nonlinear function that is applicable to complex commercial datasets. It is one of the best-normalized functions out there. With 1 and 0, it makes a clear prediction on the presence of a category. The range of this function is -infinity to + infinity.
However, the function traverses between a specific range. Sigmoids saturate and kill area gradients after some time. This results in vanishing gradients, which makes your network slow and error-prone. -
TanH results in more layers and gradients since it accepts negative input values. Negative input values have deep derivatives, which result in accurate output.
However, it also has a vanishing gradient problem. This means that when there are more layers, the derivative keeps on decreasing and, at a certain point, turns into 0. As the derivatives keep on vanishing, the activation function goes into loss.
-
ReLU is an inexpensive way of processing data mostly because it uses simple mathematical expressions in nodes of a neural network. It avoids and corrects the vanishing gradient problem.
Unfortunately, if the input surpasses the required range threshold, the function dies. The burden of pre-trained weights might not ever activate the neurons. This results in the dying ReLU problem.
- Leaky ReLU solves the inconsistencies of the ReLU function by multiplying the input variable (x) with a delta component (0.1x).
On the con side, as it is a little linear, it’s unsuitable for complex classifications, unlike Sigmoid or TanH.
-
ELU: ELU produces negative and accurate outputs that differentiate it from ReLU.
On the flip side, input values greater than zero trigger the activation to the output range of 0 to infinity.
How to choose the right activation function
While each of the above functions can classify data, you must analyze your current obstacle. You have to check the layer location, optimizers, and other parameters of your neural network. Choosing an activation function based on the error margin of different models is the way to go.
The output of each activation function differs by a huge margin, so picking the wrong one might result in an inadvertent loss for your company.
If you’re a data scientist trying to optimize your client requirements using artificial neural networks, keep the following things in mind.
- Begin with the ReLU function first, then move to other activation functions if it doesn’t create a good fit model.
-
Logistic sigmoid and TanH are restrictive functions that won’t cater to every input variable. Refrain from using these in the hidden layers of ANN.
- Use the swish function if your neural network has more than 50 layers. A swish function is an activation function by Google that can be applied to challenging domains of image classification or machine translation.
Choosing the right activation function also depends on the type of data analysis you need to perform.
1. Linear regression = linear activation function
2. Multiclass classification = softmax activation function
3.Multilabel classification = logistic sigmoid activation function
4.Convolutional neural network = ReLU activation function
Creatures from the deep
Artificial intelligence is a roadmap for end-to-end business automation. Better automation results in a better customer experience, which translates into more sales. Deep learning guides you as you navigate the ups and downs of an uncertain market, molding your data in powerful, money-driven methods.
Be more data opportunistic and realistic! Harness the power of AI and MLops software to scale your brand vision beyond your limits.

Shreya Mattoo
Shreya Mattoo is a former Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.

