Humans are bestowed with peripheral vision; but computers are rising up to competency with object detection now.
Be it Tesla Autopilot or Deebot vacuums, computing devices are fueled with novel generative AI algorithms to speed up processing powers and nomenclate physical objects. Known as object detection in a gist, this vision simulation designed with image recognition software has passed the baton of vision and sight to computers.
The primary purpose of object detection is to segment, localize and annotate physical or digital objects with foolproof precision to complete a designated task at hand.
Object detection has opened new pathways of robotic assistance which is aimed at manufacturing self-assist devices to ease tedious tasks. Let's learn about that in detail.
What is object detection?
Object detection is a narrow AI approach that identifies, classifies, and locates objects in digital photographs or videos. The main goal of object detection is to detect the instances of each object, segment them, and analyze their necessary features for real-time categorization and in-depth modularity.
Object detection is a part of the overall database architecture of a company. Some businesses have successfully adopted this technology while others are waiting for them to announce it as a successful database management technique.
Major examples of object detection include security and surveillance, access control, biometric attendance, road condition monitoring, self-assist machines, and marine border protection.
How does object detection work?
Object detection works similarly to object recognition. The only difference is that object recognition is the process of identifying the correct object category, whereas object detection simply detects the object's presence and location in an image.
Object detection tasks can be performed using two different data analysis techniques.
- Image processing is a part of unsupervised learning that doesn't require historical training data to teach analytics models. The models self-train themselves on the input images and create feature maps to make predictions. Image processing does not require high graphical processing power or large datasets for execution.
- Deep neural network: A deep neural network is generally a supervised learning algorithm that requires large datasets and high GPU computation power to predict object classes. It’s a more accurate way to classify partially hidden, complex objects, or placed in unknown backgrounds in an image.
Training a deep neural network is a labor-intensive and expensive task. However, some large-scale datasets provide the availability of labeled data.
Did you know? COCO, a large-scale object detection, segmentation, and captioning dataset, can be used to train a deep neural network.
Some features you can expect from MS COCO:
- Object segmentation
- Recognition in context
- Superpixel stuff segmentation
- Pretrained on 33OK images
- 1.5 million object instances
- 80 object classes
- 91 stuff categories
- 5 captions per image
- 250,000 people with key points
Want to learn more about Image Recognition Software? Explore Image Recognition products.
Object detection importance
Having understood the working methodology, it’s time to discuss what makes object detection important.
Object detection forms the basis for other important AI vision techniques, such as image classification, image retrieval, image processing, or object co-segmentation, which extract meaningful information from real-life objects. Developers and engineers are using these techniques to build futuristic machines that deliver groceries and medicines to our doorsteps!
An object detection algorithm can automatically detect cattle movements, traffic signals, and road lanes so self-driving vehicles can reach their destinations. This, in turn, eliminates the need for drivers to run logistic errands.

Object detection can also run on mobile networks by pruning the layers of a deep neural network. It is already being used in security scanners or metal detectors at airports to detect unwanted and illegal objects.
Apart from this, businesses use object detection for people counting, number plate recognition, speech recognition, and evidence detection. However, a slight lack of accuracy sometimes hampers its efficiency in detecting minute objects. A lack of cent percent accuracy makes it less preferable for critical domains like mining and the military.
Image classification vs. object detection
Object detection is often confused with image classification. While these are the sides of the same Rubik's cube, here are some notable differences.
-png.png)
Image classification is a simple concept of categorizing a multispectral image based on its components. If you’re given an image of a dog, the image classification model can interpret its core features and label the image as a “dog” easily. If an image contains two objects, like a cat and a dog, the model uses a multi-label classifier to classify both these objects.
The image classification model doesn’t accept any variable for object localization other than defining the object class. This is where object detection steps in.
An object detection algorithm can identify the object class and predict the exact location of the objects in an image by drawing bounding boxes around them. It’s a combination of image classification and object localization that enables the system to know where objects are placed in an image and why. It powers a system to visually analyze each object and determine its real-life application, just like humans do.
Object detection models
The most preferred approaches to object detection are machine learning or deep learning. Both methods work in conjunction with a support vector machine (SVM) to extract the features, train the algorithm, and categorize objects.
Object detection is not possible without a proper dataset. Datasets cover an object's major known features, such as location, dimensions, category, or colors. In practice, if an object detection model is pre-trained on a dataset of something with wheels, a windshield, blinkers, an engine, and a trunk, it can accurately classify the object in the given image as a car.
Different types of object detection methods have different levels of effectiveness and applicability across industries. Let’s understand this in detail :
Machine learning
The plus point of using a machine learning algorithm to perform object detection is that it relies on manually entered data for classification, not automatic training data. This makes the overall algorithm less error-prone and more stable.
Object detection is a supervised machine-learning problem, meaning you must use pre-trained models to trigger object detectors. The list of classes in the training dataset of an ML algorithm must belong to a specific image or list of images.
Machine learning approaches like natural language processing (NLP) identify and classify objects based on their illumination intensity against a backdrop. ML algorithms for 2D objects can also be reused to detect 3D objects in images.
Aggregate channel features (ACF)
ACF is a machine learning method that recognizes specific objects in an image based on a training image dataset and the objects' ground locations. It is mainly used for multi-view object detection, such as identifying 3D objects captured from three camera rigs. Self-assist vehicles, pedestrian detection, and face detection work on this principle.
ACF combines different channels that extract features from an image as gradients or pixels rather than cropping an image in various locations. Common channels include gray-scale or RBG, depending on the difficulty of the object detection problem. ACF gives you a richer understanding of objects and accelerates detection speed for higher accuracy.
Tip: To create an ACF object detector, declare and define a MATLAB programming function, “trainACFObjectDetector()” and load the training images. Test the detection accuracy on a separate test image.
DPM object detection
The deformable parts model (DPM) is a machine-learning approach that recognizes objects with a mixture of graphical models and deformable parts of the image. It contains four major components:
- A coarse root filter defines several bounding boxes in an image to capture the objects.
- Part filters cover the fragments of the objects and turn them into arrows of darker pixels.
- A spatial model stores the location of all the object fragments relative to bounding boxes in the root filter.
- A regressor decreases the distance between bounding boxes and ground truth to predict objects accurately.

Source: lilianweng.github.io/
Tip: Extracting important features of salient objects can be useful while collecting data from construction sites to track work progress or enforce environmental health and safety during work.
Deep learning
While machine learning models are built on manual selection of the features, deep learning workflows come with automatic feature selection to suit your tech stack. Deep learning approaches like convolutional neural network models produce faster and more accurate object predictions. Of course, you need a higher graphics processing unit (GPU) and larger datasets for that to happen!
Deep learning is used for a variety of object detection tasks. Modern-day video surveillance cameras or monitoring systems are powered by neural networks to successfully detect unknown faces or objects.
Here are some deep-learning approaches to tackle object detection.
You Only Look Once (YOLO)
YOLO is a single-stage object detection framework dedicated to industrial applications. Its efficient design and high performance make it hardware-friendly and efficient. It’s a CNN trained on large visual databases like image nets and can be coded in open-source editors in TensorFlow, Darknet, or Python.
YOLO produces state-of-the-art object detections at a lightning-fast 45 frames per second. To date, different versions of YOLO, such as YOLOv1, YOLOv2, or YOLOv3, have been launched.
The latest version, YOLOv6, can be trained on custom datasets in PyTorch via application programming interfaces (APIs). Pytorch is a Python package and one of the most preferred forms of deep learning research. YOLOv6 is exclusively trained to detect moving vehicles on the road.
Did you know? YOLO or region-based convolutional neural networks (R-CNN) use the mean average precision or mAP() function. It compares a ground-bounding box to an actual detected box and returns a probability or confidence score. The higher the score, the more accurate the prediction.
SSD (Single Shot Detector)
SSD is a custom object detector with no specific region proposal network (different parts of an image clubbed together in a network) for object prediction. It predicts an image's location and type of object directly in one single pass through a range of layers of a deep learning model.
SSD is bifurcated into two parts :
1. Backbone
The backbone of the pre-trained image classification network extracts the features from the image to identify the image. These networks, like ResNet, are trained on ImageNets ( large image databases) and separated from the internal image classification layer. It leaves the backbone model as a deep neural network, solely trained on millions of images to extract semantic information from the input image while preserving the spatial structure of the image.
For ResNet34, the backbone creates 256x7x7 feature maps for any input image.
2. Head
The head of the object detection model is just a neural network brain layer added to the backbone that helps in the final regression process of the image. It outputs the spatial location of the object and combines it with the object class in the final SSD stages.
Source:developers.arcgis.com
Other important components
Here are the important components that make up an SSD model to perform object detection in real time.
- Grid cell: Just like the YOLO algorithm, the SSD algorithm divides the bounding box into a 5x5 grid. Each grid cell is responsible for outputting the shape, location, color, and label of the object it contains.
- Anchor box: As the CNN divides the image into a grid, each cell in the grid is assigned more than one anchor box. SSD model uses a template matching technique during the training period to match the bounding box with each ground truth object of the image.

Source: pyimagesearch.com
Here, the predicted bounding box is drawn in red, while the ground truth bounding box (hand-labeled) is in green. As there is a high degree of overlap, this anchor box is responsible for identifying the presence of objects. The Intersection over Union (IoU) over here can be measured as
- Aspect ratio: Every object has a different shape and configuration. Some are rounder and larger, while others are shrunk and shorter. The SSD architecture helps declare aspect ratios beforehand through a ratio parameter.
- Zoom Level: The zoom parameter can magnify smaller objects in each grid cell to identify their presence, category, and location. For example, if we need to identify a building and a park from a helicopter, we need to scale the SSD algorithm in a way that it detects both the larger and the smaller objects.
- Receptive field: The receptive field is defined as the moving set of pixels of the image that the algorithm is currently working on. Different layers of a CNN model compute different regions of an input image. As it goes deeper, the size of the object increases. Just like a microscope, a CNN model magnifies every pixel of the object to compute which category it belongs to.
Intersection over Union (IoU): Area of overlap / Area of union
EfficientNet
EfficientNet is a convolutional neural network architecture that uniformly scales all the dimensions of an object before detecting them. These neural networks are developed at a fixed cost of application software. About the availability of resources, EfficientNet algorithms can be scaled across an application domain to achieve better object detection results.
EfficientNet is deemed as one of the best existing CNN models for object detection as it has achieved state-of-the-art accuracy on learning datasets like Flowers (98.8%) while being 6.1x faster than other object detection models.
Mask R-CNN
This extends Faster R-CNN by pooling the region proposal network and pre-trained CNN like AlexNet. A region proposal network is a network of regions separated by bounding boxes. Mask R-CNN extracts features from the image and creates feature maps to detect the presence of objects. It also generates a high-quality mask (bounding box) for each object to separate it from the rest.
How does Mask R-CNN work?
Mask R-CNN was built using Faster R-CNN and Fast R-CNN. While Faster R-CNN has a softmax layer that bifurcates the outputs into two parts, a class prediction and bounding box offset, Mask R-CNN is the addition of a third branch that describes the object mask which is the shape of the object. It is distinct from other categories and requires extraction of the object's graphical coordinates to accurately predict the location.
Mask R-CNN is a combination of two CNNs that works by pooling in a layer of object mask, also known as a Region of Interest (ROI), parallel with the existing bounding box locator.
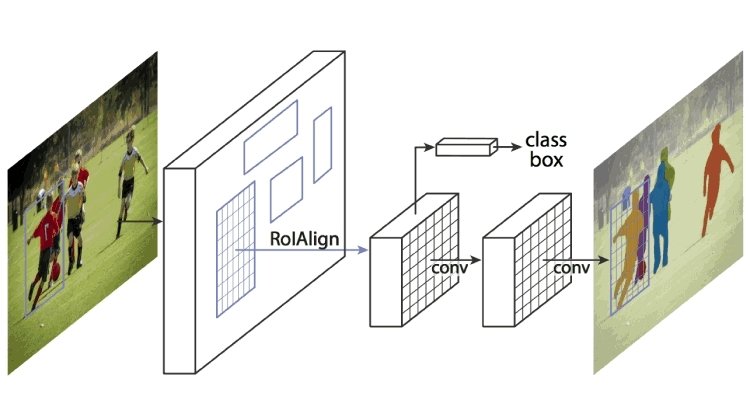
Source: viso.ai
Features of Mask R-CNN
Let’s briefly discuss a few features.
- It’s an extremely simple model to train and runs at a speed of 5 frames per second (FPS)
- It works miraculously well to detect human faces in different configurations.
- It outperforms all the single model entries on every object detection task.
- Mask R-CNN can easily generalize to other tasks. It can also be used to estimate human poses in a particular framework.
- It serves as a solid baseline to create self-assist robots that will predict our future environment.
All supervised object detection algorithms depend on labeled datasets, which means humans must apply their knowledge to train the neural network on different inputs. Label_maps can fetch the labeled objects in a dataset () functions to infer the correct object category.
What are label maps?
The label-map() in Tensorflow programming maps output numbers to the object class. If the output of an object detection algorithm is 4, this function scans the training data and returns the class corresponding to the number “4”. If “4” is mentioned as “airplane”, the output text will be “airplane”.
Object detection applications across industries
So far, object detection has achieved feats across critical domains like security, transport, medical, and military. Software companies use it to retrieve and categorize large relational datasets automatically to increase production efficiency. This process is also known as data labeling or data annotation.
Here are some real-life applications that quote the significance of AI-powered object detection systems:
- Police and forensic: Object detection can track and locate specific objects such as a person, vehicle, or backpack from frame to frame. It allows police officers and forensic professionals to inspect every nook and corner of a crime site to collect evidentiary proof. However, due to the large volume of data, the object detection process is a bit tricky and requires hours of footage to identify what can aid in the success of a case.
- Contactless checkout: Many restaurants use RFID object tracking to calculate the check amount by scanning empty plates. This process automatically adds the price of all the items to the total and eliminates the usual cash and credit transactions in a restaurant.
- Inventory and warehousing: Logistics professionals can easily detect, classify, and pick up finished goods for transportation through real-time object detection. Some companies have even developed auto-warehousing to navigate godown shelves easier. It can also automate and regulate supply chain management by tracking inventory levels to determine the optimal production flow.
- Parking system: Pre-integrated visual detectors in cars can detect open parking spaces in surface lots or parking garages. It can also provide the driver a front and rear view of the parking space and other vehicles to securely park the car.
- Disaster response: Recent fluctuations in our ecosystems, such as the deterioration of the ozone layer, increase in greenhouse gases, and global warming, have pushed developers and engineers to create object detection applications. By fine-tuning neural networks and using essential toolkits, fast and accurate models can be built for disaster response and management.
- Biometric and facial recognition: Airport security checks employ facial recognition near the departure gates to attest to the identity of travelers. Facial recognition devices compare identity documents with other biometric technologies, such as fingerprints, to prevent fraud and identity theft. During international transfers, immigration and customs departments use face matches to compare the portrait of the traveler with the picture in the passport.
Top 5 image recognition platforms
*These are the 5 leading image recognition software based on G2 Fall 2024 Grid Report in December 2024

A shield for human vision
Object detection is not just the outcome of the supercomputer generation; it’s also a promise of a secure future for humanity. Besides fueling machines with AI-enabled vision, it has discovered, analyzed, and detangled our worldly problems better than we have.
Object detection might not be extensive – yet. But it has blazed the initial path of success across business chains. There’s no going back from here.
Explore how AI is spreading beyond limits with text to speech software to support visually impaired and improve data accessibility.This article was originally published in 2022. It has been updated with new information.

Shreya Mattoo
Shreya Mattoo is a former Content Marketing Specialist at G2. She completed her Bachelor's in Computer Applications and is now pursuing Master's in Strategy and Leadership from Deakin University. She also holds an Advance Diploma in Business Analytics from NSDC. Her expertise lies in developing content around Augmented Reality, Virtual Reality, Artificial intelligence, Machine Learning, Peer Review Code, and Development Software. She wants to spread awareness for self-assist technologies in the tech community. When not working, she is either jamming out to rock music, reading crime fiction, or channeling her inner chef in the kitchen.


